Short summary:
According to Analysis of Twitter data, the upcoming elections of 1 November will result in a victory for AKP.
AKP: 47.13%
CHP: 22.35%
MHP: 18.84%
HDP: 11.68%
I will keep updating these numbers as more Twitter data is collected.
Not so short Summary:
Since the demographics of the Twitter users and the electorate of each country is unique in its own way, the boundary conditions, tuning factors and method of prediction that are fit for Turkey’ s electorate have to be determined. I have done this with data from the last election in Turkey and based on this test set, I will make a prediction about the upcoming election on 1 November.
In this blog, I will explain the research done so far.
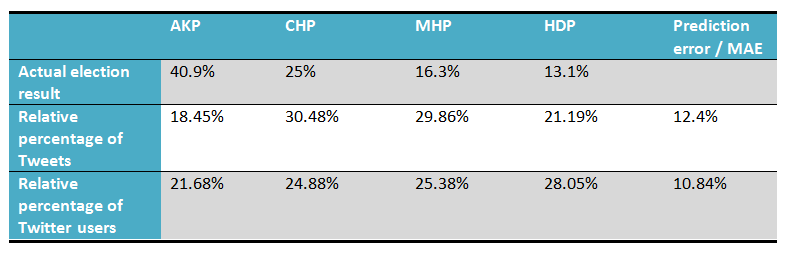
Around 936.000 Twitter messages were collected between the period of 01 may and 06 June 2015 based on a list of keywords for each party. The initial estimation deduced from the sheer volume of these Tweet messages had a prediction error (mean absolute error) of 12.4% between the predicted result and the actual election result on 7 June.
After this the Tweets were Analyzed for Sentiment (by using four different subjectivity lexicons) and classified as either positive, negative or neutral. Estimations made from the Tweets which were classified as positive (and positive – negative) did not improve the performance of the estimation.
Removing Twitter messages written by users with a suspiciously large amount of Tweets did not improve the performance of the estimation. This is probably because these users only constitute a small part of all users (only 23 of the 295.549 users have written more than 1000 messages) and the absence or presence of their Tweets does not have any significant impact.
By scraping the profile pages of the users, the location could be deduced of 66.836 users (32.4%). Removing Twitter messages from every user whose location is not known to be in Turkey actually reduced the performance of the estimation (increased the MAE from 12.4% to 15.75%). The reason for this could be that the Twitter messages were already collected in such a way that they are most likely from prospective voters (by setting the language to Turkish). Removing Twitter messages from users whose location is not known or is not in Turkey (around 70% of all users) therefore just reduces the amount of significant Tweets. Since the error in estimation cancels out relative to the quantity of collected Tweets, throwing away 70% of the collected tweets is not in our best interest.
Analyzing the dates of the collected Tweets has shown that the best result is obtained when you only take the Twitter messages in the last week before the election into consideration. Reducing the time window of the Tweets to the last week, reduces the prediction error from 12.4% down to 6.8%.
However, the biggest improvement in performance was achieved by including more names of the participating politicians as keywords when collecting Twitter messages. If all of the names of the ~550 participating politicians per party are included in the data collection phase, the volume based estimation of the prediction has a prediction error of 1.175%.
Using the same method which has led to me being able to ‘predict’ the outcome of the elections in June with an accuracy of 1.175%, I am predicting the outcome of the upcoming elections on 1 November.
Research done so far:
I was also going to write about the research done so far about predicting elections from Twitter data. But I am afraid this blog will become too long. There already is a very good article about that written by Daniel Gayo-Avello. I recommend you to read this article to gain a better understanding of the research done so far and the different methodologies and terminologies used.
Introduction:
I have collected Turkish twitter messages from the period of 01 May 2015 until Election Day (7 June 2015). Since I am only interested in the opinion of prospective voters there is no point in collecting tweets from written in any language other than Turkish or an area other than Turkey. Unfortunately Twitter messages cannot be selected on location, but it is possible to collect Twitter messages based on language.
Keywords were chosen such that the collected tweets will cover as much politics as possible.
That is, the name of the party, its abbreviation(s), the most popular two politicians, their twitter account(s), common nicknames and misspellings of these politicians were chosen as keywords, for each of the four main parties.

The collected tweets were stored in a MongoDB database together with information about which party it is collected for, which keyword it is found with, the date and time of the tweet, the tweet-id and the Twitter user. This has resulted in 936.2365 unique tweets collected.

It is clear that the predictions based on the volume of tweets (prediction error: 12.4%) or the number of Twitter users (prediction error: 10.84%) does not come close to the actual election result.
This can be due to several reasons;
- The subjectivity of each tweet is not taken into account and once it is done (Sentiment Analysis), it will reduce the prediction error.
- There are Twitter users polluting the data. Changing the boundary conditions of the dataset of users, i.e. ‘denoising’ it by removing users who have a suspiciously large amount of tweets could reduce the prediction error.
- The period of collection is not chosen optimally. Changing the period over which the tweets have been collected, either reducing it or increasing it could reduce the prediction error. For example, maybe some of the parties will increase ‘propaganda’ Tweets the week before the election and not taking these days into account could improve the results.
- The keywords are chosen poorly and a different (combination of) a subset of the keywords will lead to a better result.
- The demographics of Twitter users in Turkey are essentially different from the demographics of the general population. Taking such information into account, the tweets could be weighted to see whether this reduces the prediction error.
In the next few paragraphs I will try to find the conditions under which we can get the best performance on the estimation by addressing these issues (except for the last one).
Does Sentiment Analysis of the tweets reduce the prediction error?
Sentiment Analysis was done on the collected tweets. This was done with four different lexicons; MPQA’s Subjectivity Lexicon, Loughran and McDonald’s Master Dictionary, Bing Liu’s opinion lexicon and SentiTurkNet. The first three are originally in English and were translated to Turkish with Bing Translate. In addition to these four lexicons, each lexicon was updated with Hogenboom’s Emoticon Sentiment lexicon to take emoticons into account.
Below the results of the Sentiment Analysis is can be seen. For each dictionary the number of tweets which were scored positive and the number of tweets which were scored negative are given together with its relative value (percentage of total positive scored Tweets).
At first sight the differences seem large; with McDonald’s dictionary 736.159 tweets are scored positive while with SentiTurkNet’s dictionary only 21.247 tweets are scored positive. But this difference can partly be accounted for with the size of the dictionary (McDonald’s dictionary contains 85.131 words, BingLiu’s contains 6.789 words, MPQA’s contains 4.474 words and SentiTurkNet contains 1.498 words).

In the table above, we can see that even though there is a large difference in the absolute amount of Tweets scored positive/negative, the relative percentage of each party in this total amount of Tweets did not change much. And using a sentiment lexicon to analyse the tweets for subjectivity did not really decrease the prediction error; (12.4% for no sentiment analysis, 12.75% for MPQA, 12.57% for McDonald, 12.23% for BingLiu and 12.49% for STN)
Analyzing the users:
Remove users with a suspiciously large amount of tweets:
Now let’s have a look at the users to see if we can get better results by ‘denoising’ the dataset of users. It might be a good idea to remove users who have written an excessive amount of tweets (spammers / bots), because they do not represent the general population and probably introduce a bias in the data. After analysing the set of users we can see that largest amount of users have only written a few tweets. 117.113 users for example have only written one Tweet and another 31.393 users have only written two Tweets. As the number of Tweets goes up, the number of users who have written this many Tweets drops exponentially (see the table and figure below).


I think it is safe to say that Twitter users with less than 50 tweets (which constitute >99% of all users) can be counted among the general population. Twitter users with more than 50, 100 or 1000 tweets are either political fanatics, news agencies or Twitter bots polluting the data. How does the performance of the prediction change if we remove these users and their tweets from the dataset?

In the figures above you can see the calculated prediction error (y-axis) when users with more than a certain number of tweets (x-axis, log-scale) have been removed from the data set. As you can see the MAE does drop from 12.4% to around 11.2 % when every Twitter user with more than 8 tweets has been removed from the dataset. This is some improvement of the performance of the estimation, but not satisfying enough.
Remove the Users which are not known to be living in Turkey:
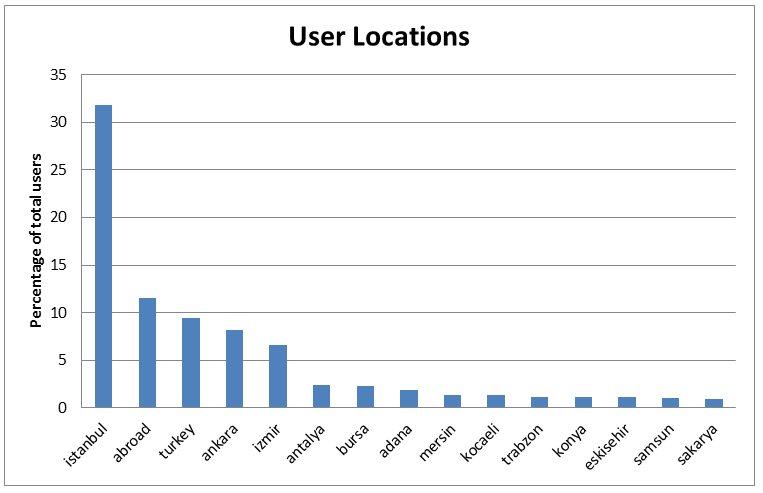
Although it is my suspicion that a high percentage of the users are already from Turkey (since I only collected Tweets written in Turkish), I do not exactly know which percentage are from Turkey and which part of Turkey they are living. It is possible however to determine the location of the users by scraping it from their Twitter profile. I did this for the 206.537 distinct users who have written the Tweets. It was possible to determine the location of 66.836 users (32.4%). From these 66.836 users, 11.57% appear to be from outside of Turkey. Most of these are however Turkish people living in various European countries; Germany, France, Netherlands, Austria etc. (And Turkish people living outside of Turkey can also vote in their country of residence).
How does the performance of the prediction change if we only include Tweets from users which are known to be living in Turkey?
Unfortunately this increases the prediction error of the estimation from 12.4% up to 15.75%. One reason for this could be that the dataset is already optimized to contain the maximum amount of Tweets from prospective voters (by setting the language to Turkish during collection). Removing all Users of which the location is not known or not in Turkey only means that ~70% of the collected Twitter messages will be thrown away. Since the error in estimation cancels out relative to the quantity of collected tweets, throwing away 70% of the collected tweets is not in our best interest.
Does changing the date-range improve the performance?
As mentioned before I had collected Tweets from the period of 01-05-15 to 06-06-15. So see whether or not the performance of the estimation improves with a different period, I can either remove any Tweet message written before a certain date or after a certain date. For example, removing any Tweet written before 05 May would probably not affect the outcome very much. But removing any Tweet written after 30 May could have a significant impact. The question I want to answer here is; do the Tweets written in the last week before Election Day have a positive or a negative impact on the performance of the estimation. And hence, does removing them decrease or increase the prediction error.
In the figure below you can see the calculated prediction error (MAE) plotted on the y-axis for two different scenarios; in the graph indicated with ‘lower cut off’ every Tweet written before the date indicated on the x-axis is removed from the dataset and the corresponding prediction error is calculated. In the graph indicated with ‘higher cut off’ this is done for every Tweet written after the dates on the x-axis.

According to this graph we get the lowest prediction error (6.8%) and hence the best performance if we cut off every Tweet written before 30 May. This means that the Tweet messages collected in the last week before the election are most representative of the voting behaviour of the Electorate.
Do a different set of keywords lead to a better result?
The research done so far was done on all Tweet messages collected with the set of keywords indicated at the beginning of the blog. Since I have saved the collected Tweets in the database together the keyword it was collected with, I can select specific subsets of keywords for each party and calculate the volume of Tweets belonging to these keywords. For example, I could select only the prime politicians, or only the party names, or only the twitter accounts of the prime politicians etc.
I have done this for a different subset of keywords, calculated the relative volume of Tweets belonging to AKP, CHP, MHP and HDP and calculated the corresponding prediction error.
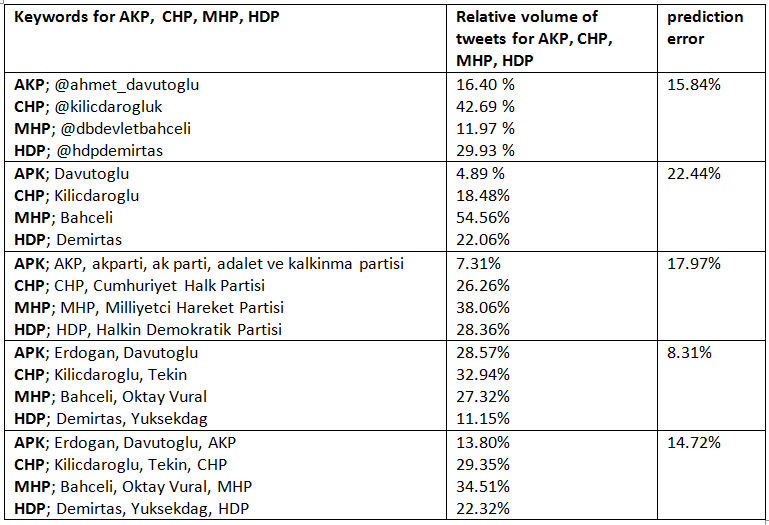
It seems that a different subset of the chosen keywords does influence the performance significantly. Collecting tweets based on the Twitter address of the most important politicians, or based on the party name does not lead to a good performance. However, choosing the keywords such that it only consists of the names of the two most important politicians of the four parties, the prediction error drops from 12.4% to 8.31%.
I guess what you are all wondering now is, what would happen to the performance when I take into consideration tweets with the names of the three / four / five most important politicians instead of the two most important ones.

As you can see, including more politician names significantly reduces the prediction error. Then, the next question to ask is how far we can take this.
So here is a crazy idea; what would happen if I scrape Twitter for Tweets including the names of all the participating politicians of all major parties in all 81 provinces? For AKP this looks something like this. This means scraping around 550 different names for each of the main party.
So I have scraped these names for the period of 01 May to 06 June resulting in 893.641 unique Tweets, and for the period of 01 April to 06 June resulting in 1.470.958 unique Tweets. These Tweets are stored in the same way except for an additional field indicating the state each politician is participating in.

As you can see, the most accurate prediction is obtained by collecting as many Tweets as possible about as many politicians participating in the election as possible. Analysis on 0.8 million Tweers written in the period of 01 May to 06 June leads to a prediction with an accuracy of 2.14%. And an analysis on 1.3 million Tweets written in the period of 01 April to 06 June leads an accuracy of 1.175 %.
So, What is my prediction?
Since the only thing that matters for an accurate result is the number of Tweets and the number of politicians, I have done similar scraping of Twitter messages containing the names of all the politicians participating in the election of 1 November. This has resulted in the following prediction:

As you can see AKP and MHP will gain some votes while CHP and HDP lose some votes. Compared to traditional Election polls I am predicting a higher percentage for AKP. This makes me a little bit nervous, but if I am wrong, I can always blame it on the dataset being too small (241.283 instead of 1.346.901)
In any case, I will keep collecting Twitter data and posting the updated predictions either on this blog or on my twitter account.
6 gedachten over “Four more years of AKP?”
Hi Ahmet,
Interesting work but have fundamental issues :
1- Using (mean absolute error) for dependent events. People’s political opinion/sentiments are not random/seasonal events (though indirectly affected from random events). Therefore bayesian methods are required for such analysis.
2- Sampling issue. I do not know how in Turkey twitter users can represent the whole population.
3- Sentiment analysis is the key point here together with prediction error (which is broken as I said at point 1) and then it is being performed by translating lexicons via bing mostly. This will add also lots of error. I am also generally skeptical about this method because of cultural differences. Turkish people tend to have different sentimental patterns.
So overall you try to fit to last elections results by playing around different data by using a wrong prediction error estimator. On top of that you don’t have a sound sampling at your hands. You have no model, no confidence interval…
It is more like guesstimate which does not require this much work unless you have some other motivations. I appreciate your effort though.
Cheers,
Ijon
Thank you for the response Ijon,
As you probably know some metric has to be chosen to calculate the probable voting distribution of the Electorate (of Turkey). This metric can be the volume of Tweets, the volume of Tweets which were classified as positive with Sentiment Analysis, The number of Twitter users, The number of retweets from political leaders etc etc.
I have chosen the volume of Tweets, because I found from the training data that the distribution of the volume of Tweets can accurately reflect the actual distribution of votes, if the keywords are chosen carefully. (And hence that Twitter can be used to inform us about the electorate’s political sentiment.)
It would have been nice to do a proper sentiment Analysis on the collected Tweets to see if the distribution of the number of positively classified Tweets (for example) comes more close to the actual distribution of votes. There were several reasons why I have not done a proper Sentiment Analysis on the collected Tweets.
1. There is a lack of Turkish Sentiment Lexicon. There is one Sentiment Lexicon (SentiTurkNet) which was independently created in the Turkish language. However I was confronted with two problems during the use of this lexicon; most verbs in this lexicon appear in their base form (like “rahatlatmak ; hafifletmek ; azaltmak”) and I don’t think anybody talks like that in the colloquial Turkish (and especially on Twitter). I did not find there to be any problem with for example the nouns in the lexicon, but this also brings me to the second problem; SentiTurkNet does not contain that many words (~1500) compared to the English lexicons (~8200 in MPQA’s, ~6800 in BingLiu’s, 85.000 in McDonald’s Lexicon). I know that a proper way to translate these English Dictionaries to Turkish is to use two independent dictionaries, producing a confidence interval for each translation and removing (or manually translating) words which have a low confidence interval (see MLSN: A multi-lingual semantic network by Daniel Cook). The proper way to translate English lexicons to Turkish would take much more time than I had (due to the impending deadline of Election day and due to my full time job).
2. Most researchers who have tried to increase the accuracy of the estimation with lexicon based methods, have found that Sentiment Analysis only leads to minor improvements (see more details in the comparative study by Daniel Gayo-Avello). This is probably because they used “the simplest of methods” only using binary classification of individual words, not taking into account grammatical subtleties. I do think eventually we will be able to optimize lexicon based methods and very accurately analyse the sentiment of texts in an automated way, but at the moment I am still sceptical. That is why I did not put any emphasis on Sentiment Analysis.
3. I had already found a satisfying results using the distribution of the number of Tweets alone, which left me with little motivation to do proper sentiment analysis.
If the demographics of the Turkish Electorate and the Turkish Twitter users and the differences between them are be taken into account, this could lead to a further increase in the accuracy of the estimation. I agree with you there. Although there are some researches done on the Turkish electorate (by KONDA for example), I could not find that many researches done on the Twitter population of Turkey. I am aware of Genart and Nielsen, but nothing else. What I have seen in my own data is that most of the Twitter users are tweeting from larger places like Istanbul, Izmir, Ankara etc. All of the provinces have a large amount of Twitter users tweeting about politics. For example, in the initial dataset about 6500 users were detected to be from Ardahan, which is the province with the least amount of users. Although this seems a lot, it is in stark contrast with Istanbul (about 93.680 detected users). What this means is that predictions made on the provincial level become quiet inaccurate quiet fast. Most of the provinces do not have enough Twitter users tweeting about politics to make a statement with a high probability on provincial level.
Like I said before, I hope the distribution of Tweets accurately reflects the political landscape of Turkey. I will keep updating the initial numbers as I collect more data. But since you are the statistics expert here, what would you recommend me to use as a measure for accuracy of the prediction?
“what would you recommend me to use as a measure for accuracy of the prediction”
Actually I had answered it : Use a bayes estimator. You have former elections as prior information. What you need now is (taking into account that party X took %Y votes) by considering the sentiment of a twitter finding the probability that he/she voted for party X (which will also represent the unknown population better).
So this requires Bayesian approach. Then you can turn the question upside down and estimate the elections with obtained prior probabilities combined with new data.
Still you will need a very sound sentiment analysis.
or you wait for an unknown time until twitter is wide spread in Turkey so you can have better sampling options. Still you would need some information regarding the users to be able to make your sampling a good representative of Turkey.
so actually it is difficult to catch via Twitter, what traditional survey companies are doing. They have well designed questionnaires and well designed sampling of population.
in the end you can not blame your data size but you can only blame random error / bias you introduced while you were trying to minimize mean absolute error.
there are already many surveys published and AKP is around %39-42. AKP got %40 in the last elections. %7 percent increase could be only achieved by magic in this short time frame. Even though it is possible to lie with statistics still it is not possible to do magic (fortunately:))
have fun and success 😉
Candide Ijon, what do you make of the election results?
https://en.wikipedia.org/wiki/Turkish_general_election,_November_2015#Overall_results
@Erik Jan de Vries
I think results are pretty bad for Turkey.
If you are asking in the context of this post, I do not think the methodologies that is used here is proper. So having something close to actual results does not change my mind. You can guess in the band of %39-%47 (which was the range given by surveys) and as we have seen it was even higher than that.
I explained why I found this analysis not a proper one but just a guesstimate.
Twitter data is very insufficient to represent Turkey. Particularly the voters of AKP if we get %47 based on Twitter AKP should actually get much higher in reality because they are very strong in rural areas where people do not use twitter. So how can you estimate that large portion of population with non existing data ?
On top of that sentiment analysis looks pretty insufficient without the availability of Turkish words or phrases.
I could just make up an analysis myself and pitch %45. Being 4 percent lower than actual would not mean anything. You need sound scientific methods and should be able to give confidence intervals.
And what about yourself ? what do you think ?
Apparantly, Twitter data is NOT that insufficient as it may seem. I believe one can take a positive outlook from this ‘simple’ approach with the possibilities of improvement and therefore more accurate predictions.
I think this person did a very nice job, while I agree the methods could be better. Furthermore, you can not ‘just’ make an analysis and pitch 45% and base your imaginative conclusions from it.