update: the dataset containing the book-reviews of Amazon.com has been added to the UCI Machine Learning repository.
Introduction:
In my previous post I have explained the Theory behind three of the most popular Text Classification methods (Naive Bayes, Maximum Entropy and Support Vector Machines) and told you that I will use these Classifiers for the automatic classification of the subjectivity of Amazon.com book reviews.
The purpose is to get a better understanding of how these Classifiers work and perform under various conditions, i.e. do a comparative study about Sentiment Analytics.
In this blog-post we will use the bag-of-words model to do Sentiment Analysis. The bag-of-words model can perform quiet well at Topic Classification, but is inaccurate when it comes to Sentiment Classification. Bo Pang and Lillian Lee report an accuracy of 69% in their 2002 research about Movie review sentiment analysis. With the three Classifiers this percentage goes up to about 80% (depending on the chosen feature).
The reason to still make a bag-of-words model is that it gives us a better understanding of the content of the text and we can use this to select the features for the three classifiers. The Naive Bayes model is also based on the bag-of-words model, so the bag-of-words model can be used as an intermediate step.
Data Collection:
We can collect book reviews from Amazon.com by scraping them from the website with BeautifulSoup. The process for this was already explained in the context of Twitter.com and it should not be too difficult to do the same for Amazon.com.
In total 213.335 book reviews were collected for eight randomly chosen books:
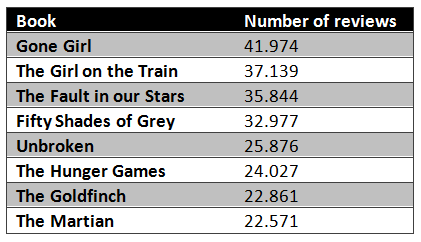
After making a bar-plot of the distribution of the different stars for the chosen books, we can we that there is a strong variation. Books which are considered to be average have almost no 1-star ratings while books far below average have a more uniform distribution of the different ratings.

We can see that the book ‘Gone Girl’ has a pretty uniform distribution so it seems like a good choice for our training set. Books like ‘Unbroken’ or ‘The Martian’ might not have enough 1-star reviews to train for the Negative class.
Creating a bag-of-words model
As the next step, we are going to divide the corpus of reviews into a training set and a test set. The book ‘Gone Girl’ has about 40.000 reviews, so we can use up to half of it for training purposes and the other half for testing the accuracy of our model. In order to also take into account the effects of the training set size on the accuracy of our model, we will vary the training set size from 1.000 up to 20.000.
The bag-of-words model is one of the simplest language models used in NLP. It makes an unigram model of the text by keeping track of the number of occurences of each word. This can later be used as a features for Text Classifiers. In this bag-of-words model you only take individual words into account and give each word a specific subjectivity score. This subjectivity score can be looked up in a sentiment lexicon[1]. If the total score is negative the text will be classified as negative and if its positive the text will be classified as positive. It is simple to make, but is less accurate because it does not take the word order or grammar into account.
A simple improvement on using unigrams would be to use unigrams + bigrams. That is, not split a sentence after words like “not”,”no”,”very”, “just” etc. It is easy to implement but can give significant improvement to the accuracy. The sentence “This book is not good” will be interpreted as a positive sentence, unless such a construct is implemented. Another example is that the sentences “This book is very good” and “This book is good” will have the same score with a unigram model of the text, but not with an unigram + bigram model.
My pseudocode for creating a bag-of-words model is as follows:
- list_BOW = []
- For each review in the training set:
- Strip the newline charachter “n” at the end of each review.
- Place a space before and after each of the following characters: .,()[]:;” (This prevents sentences like “I like this book.It is engaging” being interpreted as [“I”, “like”, “this”, “book.It”, “is”, “engaging”].)
- Tokenize the text by splitting it on spaces.
- Remove tokens which consist of only a space, empty string or punctuation marks.
- Append the tokens to list_BOW.
- list_BOW now contains all words occuring in the training set.
- Place list_BOW in a Python Counter element. This counter now contains all occuring words together with their frequencies. Its entries can be sorted with the most_common() method.
Making the Sentiment Lexicon
The real question is, how we should determine the sentiment/subjectivity score of each word in order to determine the total subjectivity score of the text. We can use one of the sentiment lexicons given in [1], but we dont really know in which circumstances and for which purposes these lexicons are created. Furthermore, in most of these lexicons the words are classified in a binary way (either positive or negative ). Bing Liu’s sentiment lexicon for example contains a list of a few thousands positive and a few thousand negative words.
Bo Pang and Lillian Lee used words which were chosen by two student as positive and negative words.
It would be better if we determine the subjectivity score of each word using some simple statistics of the training set. To do this we need to determine the class probability of each word present in the bag-of-words. This can be done by using pandas dataframe as a datacontainer (but can just as easily be done with dictionaries or other data structures). The code for this looks like:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
from sets import Set import pandas as pd BOW_df = pd.DataFrame(0, columns=scores, index='') words_set = Set() for review in training_set: score = review['score'] text = review['review_text'] splitted_text = split_text(text) for word in splitted_text: if word not in words_set: words_set.add(word) BOW_df.loc[word] = [0,0,0,0,0] BOW_df.ix[word][score] += 1 else: BOW_df.ix[word][score] += 1 |
Here split_text is the method for splitting a text into a list of individual words:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
def expand_around_chars(text, characters): for char in characters: text = text.replace(char, " "+char+" ") return text def split_text(text): text = strip_quotations_newline(text) text = expand_around_chars(text, '".,()[]{}:;') splitted_text = text.split(" ") cleaned_text = [x for x in splitted_text if len(x)>1] text_lowercase = [x.lower() for x in cleaned_text] return text_lowercase |
This gives us a DataFrame containing of the number of occurances of each word in each class:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
Unnamed: 0 1 2 3 4 5 0 i 4867 5092 9178 14180 17945 1 through 210 232 414 549 627 2 all 499 537 923 1355 1791 3 drawn-out 1 0 1 1 0 4 , 4227 4779 8750 15069 18334 5 detailed 3 7 15 30 36 ... ... ... ... ... ... ... 31800 a+++++++ 0 0 0 0 1 31801 nailbiter 0 0 0 0 1 31802 melinda 0 0 0 0 1 31803 reccomend! 0 0 0 0 1 31804 suspense!! 0 0 0 0 1 [31804 rows x 6 columns] |
As we can see there are also quiet a few words which only occur one time. These words will have a class probability of 100% for the class they are occuring in.
This distribution however, does not approximate the real class distribution of that word at all. It is therefore good to define some ‘occurence cut off value’; words which occur less than this value are not taken into account.
By dividing each element of each row by the sum of the elements of that row we will get a DataFrame containing the relative occurences of each word in each class, i.e. a DataFrame with the class probabilities of each word. After this is done, the words with the highest probability in class 1 can be taken as negative words and words with the highest probability in class 5 can be taken as positive words.
We can construct such a sentiment lexicon from the training set and use it to measure the subjectivity of reviews in the test set. Depending on the size of the training set, the sentiment lexicon becomes more accurate for prediciton.

Determining the Subjectivity of the reviews
By labeling 4 and 5-star reviews as Positive, 1 and 2-star reviews as Negative and 3 star reviews as Neutral and using the following positive and negative word:

we can determine with the bag-of-words model whether a review is positive or negative with a 60% accuracy .
What’s Next:
- How accurate is this list of positive and negative words constructed from the reviews of book A in determening the subjectivity of book B reviews.
- How much more accurate will the bag-of-words model become if we take bigrams or even trigrams into account? There were words with a high negative or positive subjectivity in the word-list which do not have a negative or positive meaning by themselves. This can only be understood if you take the preceding or following words into account.
- Make an overall sentiment lexicon from all the reviews of all the books.
- Use the bag-of-words as features for the Classifiers; Naive Bayes, Maximum Entropy and Support Vector Machines.
11 gedachten over “Sentiment Analysis with bag-of-words”
need some help with NLP text analysis of survey dta
hey Ahmet!
BOW_df = pd.DataFrame(0, columns=scores, index=”)
what does this statement do? Can’t we use words directly from the bag_of _words model?instead of recreating everything?
Also, can you explain this too?
BOW_df.loc[word] = [0,0,0,0,0]
BOW_df.ix[word][score] += 1
else:
BOW_df.ix[word][score] += 1
Thankyou!
Hi Aruna,
That is some old code. I’m not sure I would have done it similarly right now.
In any case, the idea behind it is/was that if a word is not present in the dataframe, I first have to add it to the dataframe, and initialize that row with zeroes. After that is done, I can update the appropriate column with +1.
With hindsight. another way you could do it is like this:
——————
from collections import defaultdict, Counter
dict_bow = defaultdict(list)
for review in training_set:
score = review['score']
splitted_text = split_text(review['review_text'])
dict_bow[score] += splitted_text
for key in dict_bow.keys():
dict_bow[key] = list(Counter(dict_bow[key]).most_common())
————
In the code above, indentations are not shown properly, but here is how it works.
dict_bow is a dictionary and it has as keys the classes/labels, and as values a list of all occurring words for each class.
These lists do contain multiple values of the same word. With Counter().most_common() you can turn the list of all words into a list of tuples of containing the word, and the no of occurrences of that word.
If you want to work with relative occurrence instead of absolute occurrence, you need to remember how long that list was (i.e. how many words there were), and divide each occurrence value by the list length.