1. Introduction
Most tasks in Machine Learning can be reduced to classification tasks. For example, we have a medical dataset and we want to classify who has diabetes (positive class) and who doesn’t (negative class). We have a dataset from the financial world and want to know which customers will default on their credit (positive class) and which customers will not (negative class).
To do this, we can train a Classifier with a ‘training dataset’ and after such a Classifier is trained (we have determined its model parameters) and can accurately classify the training set, we can use it to classify new data (test set). If the training is done properly, the Classifier should predict the class probabilities of the new data with a similar accuracy.
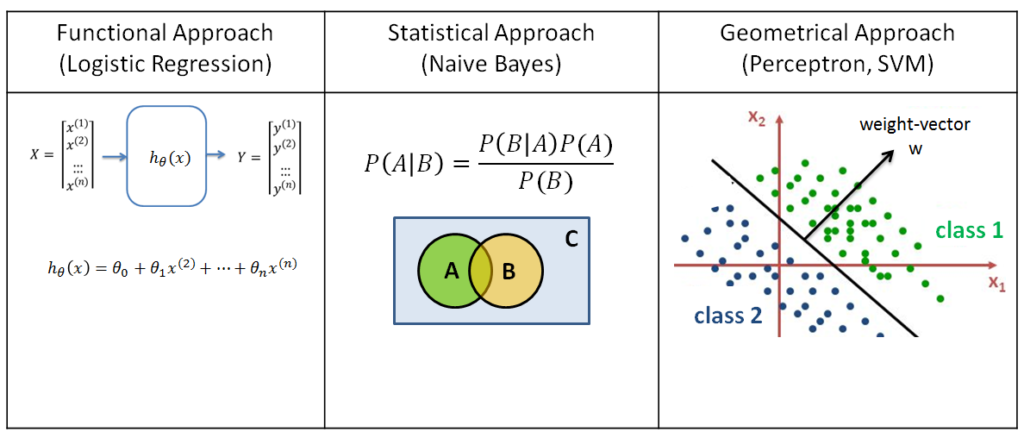
There are three popular Classifiers which use three different mathematical approaches to classify data. Previously we have looked at the first two of these; Logistic Regression and the Naive Bayes classifier. Logistic Regression uses a functional approach to classify data, and the Naive Bayes classifier uses a statistical (Bayesian) approach to classify data.
Logistic Regression assumes there is some function  which forms a correct model of the dataset (i.e. it maps the input values correctly to the output values). This function is defined by its parameters
which forms a correct model of the dataset (i.e. it maps the input values correctly to the output values). This function is defined by its parameters  . We can use the gradient descent method to find the optimum values of these parameters.
. We can use the gradient descent method to find the optimum values of these parameters.
The Naive Bayes method is much simpler than that; we do not have to optimize a function, but can calculate the Bayesian (conditional) probabilities directly from the training dataset. This can be done quiet fast (by creating a hash table containing the probability distributions of the features) but is generally less accurate.
Classification of data can also be done via a third way, by using a geometrical approach. The main idea is to find a line, or a plane, which can separate the two classes in their feature space. Classifiers which are using a geometrical approach are the Perceptron and the SVM (Support Vector Machines) methods.
Below we will discuss the Perceptron classification algorithm. Although Support Vector Machines is used more often, I think a good understanding of the Perceptron algorithm is essential to understanding Support Vector Machines and Neural Networks.
1.2 Multiclass Classification
The Perceptron is a lightweight algorithm, which can classify data quiet fast. But it only works in the limited case of a linearly separable, binary dataset. If you have a dataset consisting of only two classes, the Perceptron classifier can be trained to find a linear hyperplane which seperates the two. If the dataset is not linearly separable, the perceptron will fail to find a separating hyperplane.
If the dataset consists of more than two classes we can use the standard approaches in multiclass classification (one-vs-all and one-vs-one) to transform the multiclass dataset to a binary dataset. For example, if we have a dataset, which consists of three different classes:
- In one-vs-all, class I is considered as the positive class and the rest of the classes are considered as the negative class. We can then look for a separating hyperplane between class I and the rest of the dataset (class II and III). This process is repeated for class II and then for class III. So we are trying to find three separating hyperplanes; between class I and the rest of the data, between class II and the rest of the data, etc.
If the dataset consists of K classes, we end up with K separating hyperplanes. - In one-vs-one, class I is considered as the positive class and each of the other classes is considered as the negative class; so first class II is considered as the negative class and then class III is is considered as the negative class. Then this process is repeated with the other classes as the positive class.
So if the dataset consists of K classes, we are looking for separating hyperplanes.
separating hyperplanes.
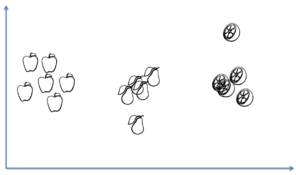
Although the one-vs-one can be a bit slower (there is one more iteration layer), it is not difficult to imagine it will be more advantageous in situations where a (linear) separating hyperplane does not exist between one class and the rest of the data, while it does exists between one class and other classes when they are considered individually. In the image below there is no separating line between the pear-class and the other two classes.
1.3 Perceptrons and Support Vector Machines
The algorithm for the Perceptron is similar to the algorithm of Support Vector Machines (SVM). Both algorithms find a (linear) hyperplane separating the two classes. The biggest difference is that the Perceptron algorithm will find any hyperplane, while the SVM algorithm uses a Lagrangian constraint to find the hyperplane which is optimized to have the maximum margin. That is, the sum of the squared distances of each point to the hyperplane is maximized. This is illustrated in the figure below. While the Perceptron classifier is satisfied if any of these seperating hyperplanes are found, a SVM classifier will find the green one , which has the maximum margin.
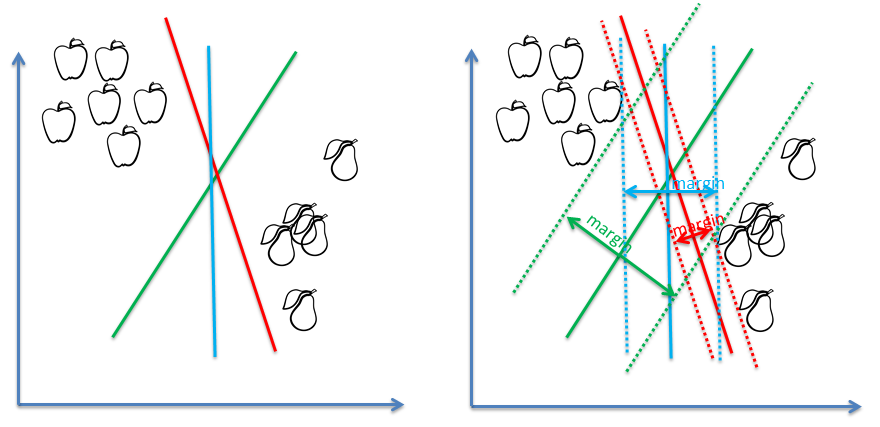
Another difference is; If the dataset is not linearly seperable [2] the perceptron will fail to find a separating hyperplane. The algorithm simply does not converge during its iteration cycle. The SVM on the other hand, can still find a maximum margin minimum cost decision boundary (a separating hyperplane which does not separate 100% of the data, but does it with some small error).
2. The Perceptron Algorithm:
It is often said that the perceptron is modeled after neurons in the brain. It has  input values (which correspond with the features of the examples in the training set) and one output value. Each input value
input values (which correspond with the features of the examples in the training set) and one output value. Each input value  is multiplied by a weight-factor
is multiplied by a weight-factor  . If the sum of the products between the feature value and weight-factor is larger than zero, the perceptron is activated and ‘fires’ a signal (+1). Otherwise it is not activated.
. If the sum of the products between the feature value and weight-factor is larger than zero, the perceptron is activated and ‘fires’ a signal (+1). Otherwise it is not activated.
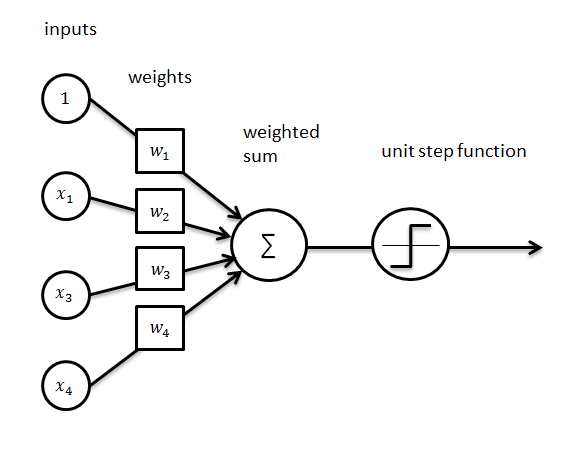
The weighted sum between the input-values and the weight-values, can mathematically be determined with the scalar-product  . To produce the behaviour of ‘firing’ a signal (+1) we can use the signum function
. To produce the behaviour of ‘firing’ a signal (+1) we can use the signum function  it maps the output to +1 if the input is positive, and it maps the output to -1 if the input is negative.
it maps the output to +1 if the input is positive, and it maps the output to -1 if the input is negative.
Thus, this Perceptron can mathematically be modeled by the function  . Here
. Here  is the bias, i.e. the default value when all feature values are zero.
is the bias, i.e. the default value when all feature values are zero.
The perceptron algorithm looks as follows:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
class Perceptron(): """ Class for performing Perceptron. X is the input array with n rows (no_examples) and m columns (no_features) Y is a vector containing elements which indicate the class (1 for positive class, -1 for negative class) w is the weight-vector (m number of elements) b is the bias-value """ def __init__(self, b = 0, max_iter = 1000): self.max_iter = max_iter self.w = [] self.b = 0 self.no_examples = 0 self.no_features = 0 def train(self, X, Y): self.no_examples, self.no_features = np.shape(X) self.w = np.zeros(self.no_features) for ii in range(0, self.max_iter): w_updated = False for jj in range(0, self.no_examples): a = self.b + np.dot(self.w, X[jj]) if np.sign(Y[jj]*a) != 1: w_updated = True self.w += Y[jj] * X[jj] self.b += Y[jj] if not w_updated: print("Convergence reached in %i iterations." % ii) break if w_updated: print( """ WARNING: convergence not reached in %i iterations. Either dataset is not linearly separable, or max_iter should be increased """ % self.max_iter ) def classify_element(self, x_elem): return int(np.sign(self.b + np.dot(self.w, x_elem))) def classify(self, X): predicted_Y = [] for ii in range(np.shape(X)[0]): y_elem = self.classify_element(X[ii]) predicted_Y.append(y_elem) return predicted_Y |
As you can see, we set the bias-value and all the elements in the weight-vector to zero. Then we iterate ‘max_iter’ number of times over all the examples in the training set.
Here, ![Y[ii]](https://ataspinar.com/wp-content/ql-cache/quicklatex.com-a9acf21666b264d54ee8b046c8175b73_l3.svg "Rendered by QuickLaTeX.com") is the actual output value of each training example. This is either +1 (if it belongs to the positive class) or -1 (if it does not belong to the positive class).,
is the actual output value of each training example. This is either +1 (if it belongs to the positive class) or -1 (if it does not belong to the positive class).,
The activation function value  is the predicted output value. It will be
is the predicted output value. It will be  if the prediction is correct and
if the prediction is correct and  if the prediction is incorrect. Therefore, if the prediction made (with the weight vector from the previous training example) is incorrect,
if the prediction is incorrect. Therefore, if the prediction made (with the weight vector from the previous training example) is incorrect,  will be -1, and the weight vector
will be -1, and the weight vector  is updated.
is updated.
If the weight vector is not updated after some iteration, it means we have reached convergence and we can break out of the loop.
If the weight vector was updated in the last iteration, it means we still didnt reach convergence and either the dataset is not linearly separable, or we need to increase ‘max_iter’.
We can see that the Perceptron is an online algorithm; it iterates through the examples in the training set, and for each example in the training set it calculates the value of the activation function  and updates the values of the weight-vector.
and updates the values of the weight-vector.
2.2 Example: 2D
Now lets examine the Perceptron algorithm for a linearly separable dataset which exists in 2 dimensions. For this we first have to create this dataset:
|
1 2 3 4 5 6 7 8 |
def generate_data(no_points): X = np.zeros(shape=(no_points, 2)) Y = np.zeros(shape=no_points) for ii in range(no_points): X[ii][0] = random.randint(1,9)+0.5 X[ii][1] = random.randint(1,9)+0.5 Y[ii] = 1 if X[ii][0]+X[ii][1] >= 13 else -1 return X, Y |
In the 2D case, the perceptron algorithm looks like:
|
1 2 3 4 5 6 |
X, Y = generate_data(100) p = Perceptron() p.train(X, Y) X_test, Y_test = generate_data(50) predicted_Y_test = p.classify(X_test) |
As we can see, the weight vector and the bias ( which together determine the separating hyperplane ) are updated when  is not positive.
is not positive.
The result is nicely illustrated in this gif:
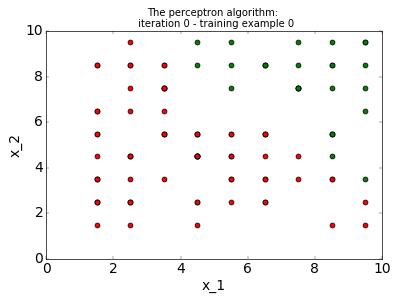
We can extend this to a dataset in any number of dimensions, and as long as it is linearly separable, the Perceptron algorithm will converge.
2.3 Kernel Perceptrons
One of the benefits of this Perceptron is that it is a very ‘lightweight’ algorithm; it is computationally very fast and easy to implement for datasets which are linearly separable. But if the dataset is not linearly separable, it will not converge.
For such datasets, the Perceptron can still be used if the correct kernel is applied. In practice this is never done, and Support Vector Machines are used whenever a Kernel needs to be applied. Some of these Kernels are:
| Linear: | |
| Polynomial: |  with with  |
| Laplacian RBF: |  |
| Gaussian RBF: |  |
At this point, it will be too much to also implement Kernel functions, but I hope to do it at a next post about SVM. For more information about Kernel functions, a comprehensive list of kernels, and their source code, please click here.
PS: The Python code for Logistic Regression can be forked/cloned from GitHub.
10 gedachten over “The Perceptron”
thanks for this explanation. I am still learning ML so this is very useful.
This was really helpful my friend. You are a lifesaver and a teacher. THANK YOU
Y[ii] = 1 if X[ii][0]+X[ii][1] >= 13 else -1
Hi. Friend.Could you please me to explain this code? I cannot understand it .
Thank you.
Hi Jimmy,
There I am simply generating the labels for our a binary dataset. If it lies below “y = 13 – x”, it belongs to the class -1, otherwise it belongs to the class 1.
Hello ataspinar,
Nice work, one of the best tutorials about practical perpeptron that I ever read.
I think there is an error in your code/function to generate to graph points in example: 2D.
This line:
> Y[ii] = 1 if X[ii][0]+X[ii][1] >= 13 else -1
‘ gt;= ‘ is it right ? And ‘ gt ‘ is not defined .
Hi Wil,
“gt;” should be “>”. Somehow greater than and smaller than symbols are not parsed correctly.
Nice !!!
on blog ‘gt’ turned ‘>’ haha
Thanks for the attention
How plot in code the hyperplane in this example ? I know that I need to use weight vector, but does the bias too ? I haven’t practical picture in my mind.
Hi Wil,
In the case of the 2D plot, it works like this.
Normally if you plot the line “y = c + d*x”, then “c” indicates the bias (what is the value for y at x=0), and “d” indicates the slope.
In our case, c = -b/w[1] and d = -w[0]/w[1].
So the line can be expressed as “y = -b/w[1] – (w[0]/w[1])*x”.