1. Introduction
In a previous blog-post we have seen how we can use Signal Processing techniques for the classification of time-series and signals.
A very short summary of that post is: We can use the Fourier Transform to transform a signal from its time-domain to its frequency domain. The peaks in the frequency spectrum indicate the most occurring frequencies in the signal. The larger and sharper a peak is, the more prevalent a frequency is in a signal. The location (frequency-value) and height (amplitude) of the peaks in the frequency spectrum then can be used as input for Classifiers like Random Forest or Gradient Boosting.
This simple approach works surprisingly well for many classification problems. In that blog post we were able to classify the Human Activity Recognition dataset with a ~91 % accuracy.
The general rule is that this approach of using the Fourier Transform will work very well when the frequency spectrum is stationary. That is, the frequencies present in the signal are not time-dependent; if a signal contains a frequency of x  this frequency should be present equally anywhere in the signal.
this frequency should be present equally anywhere in the signal.
The more non-stationary/dynamic a signal is, the worse the results will be. That’s too bad, since most of the signals we see in real life are non-stationary in nature. Whether we are talking about ECG signals, the stock market, equipment or sensor data, etc, etc, in real life problems start to get interesting when we are dealing with dynamic systems. A much better approach for analyzing dynamic signals is to use the Wavelet Transform instead of the Fourier Transform.
Even though the Wavelet Transform is a very powerful tool for the analysis and classification of time-series and signals, it is unfortunately not known or popular within the field of Data Science. This is partly because you should have some prior knowledge (about signal processing, Fourier Transform and Mathematics) before you can understand the mathematics behind the Wavelet Transform. However, I believe it is also due to the fact that most books, articles and papers are way too theoretical and don’t provide enough practical information on how it should and can be used.
In this blog-post we will see the theory behind the Wavelet Transform (without going too much into the mathematics) and also see how it can be used in practical applications. By providing Python code at every step of the way you should be able to use the Wavelet Transform in your own applications by the end of this post.
The contents of this blogpost are as follows:
- Introduction
- Theory
- 2.1 From Fourier Transform to Wavelet Transform
- 2.2 How does the Wavelet Transform work?
- 2.3 The different types of Wavelet families
- 2.4 Continuous Wavelet Transform vs Discrete Wavelet Transform
- 2.5 More on the Discrete Wavelet Transform: The DWT as a filter-bank.
- Practical Applications
- 3.1 Visualizing the State-Space using the Continuous Wavelet Transform
- 3.2 Using the Continuous Wavelet Transform and a Convolutional Neural Network to classify signals
- 3.2.1 Loading the UCI-HAR time-series dataset
- 3.2.2 Applying the CWT on the dataset and transforming the data to the right format
- 3.2.3 Training the Convolutional Neural Network with the CWT
- 3.3 Deconstructing a signal using the DWT
- 3.4 Removing (high-frequency) noise using the DWT
- 3.5 Using the Discrete Wavelet Transform to classify signals
- 3.5.1 The idea behind Discrete Wavelet classification
- 3.5.2 Generating features per sub-band
- 3.5.3 Using the features and scikit-learn classifiers to classify two datasets.
- 3.6 Comparison of the classification accuracies between DWT, Fourier Transform and Recurrent Neural Networks
- Finals Words
PS: In this blog-post we will mostly use the Python package PyWavelets, so go ahead and install it with pip install pywavelets.
2.1 From Fourier Transform to Wavelet Transform
In the previous blog-post we have seen how the Fourier Transform works. That is, by multiplying a signal with a series of sine-waves with different frequencies we are able to determine which frequencies are present in a signal. If the dot-product between our signal and a sine wave of a certain frequency results in a large amplitude this means that there is a lot of overlap between the two signals, and our signal contains this specific frequency. This is of course because the dot product is a measure of how much two vectors / signals overlap.
The thing about the Fourier Transform is that it has a high resolution in the frequency-domain but zero resolution in the time-domain. This means that it can tell us exactly which frequencies are present in a signal, but not at which location in time these frequencies have occurred. This can easily be demonstrated as follows:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
t_n = 1 N = 100000 T = t_n / N f_s = 1/T xa = np.linspace(0, t_n, num=N) xb = np.linspace(0, t_n/4, num=N/4) frequencies = [4, 30, 60, 90] y1a, y1b = np.sin(2*np.pi*frequencies[0]*xa), np.sin(2*np.pi*frequencies[0]*xb) y2a, y2b = np.sin(2*np.pi*frequencies[1]*xa), np.sin(2*np.pi*frequencies[1]*xb) y3a, y3b = np.sin(2*np.pi*frequencies[2]*xa), np.sin(2*np.pi*frequencies[2]*xb) y4a, y4b = np.sin(2*np.pi*frequencies[3]*xa), np.sin(2*np.pi*frequencies[3]*xb) composite_signal1 = y1a + y2a + y3a + y4a composite_signal2 = np.concatenate([y1b, y2b, y3b, y4b]) f_values1, fft_values1 = get_fft_values(composite_signal1, T, N, f_s) f_values2, fft_values2 = get_fft_values(composite_signal2, T, N, f_s) fig, axarr = plt.subplots(nrows=2, ncols=2, figsize=(12,8)) axarr[0,0].plot(xa, composite_signal1) axarr[1,0].plot(xa, composite_signal2) axarr[0,1].plot(f_values1, fft_values1) axarr[1,1].plot(f_values2, fft_values2) (...) plt.tight_layout() plt.show() |
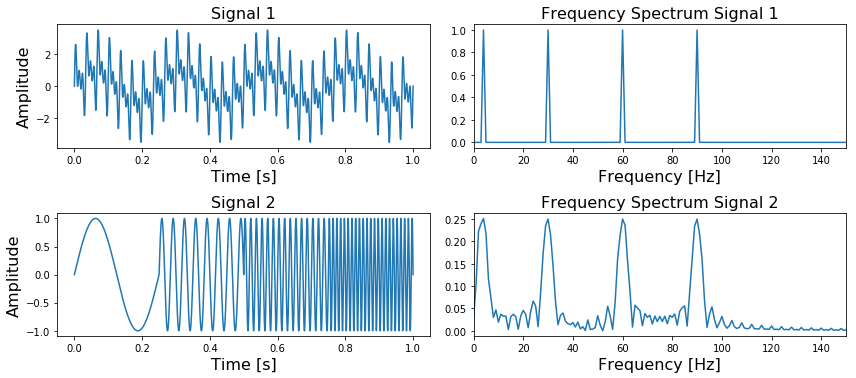
In Figure 1 we can see at the top left a signal containing four different frequencies ( ,
,  ,
,  and
and  ) which are present at all times and on the right its frequency spectrum. In the bottom figure, we can see the same four frequencies, only the first one is present in the first quarter of the signal, the second one in the second quarter, etc. In addition, on the right side we again see its frequency spectrum.
) which are present at all times and on the right its frequency spectrum. In the bottom figure, we can see the same four frequencies, only the first one is present in the first quarter of the signal, the second one in the second quarter, etc. In addition, on the right side we again see its frequency spectrum.
What is important to note here is that the two frequency spectra contain exactly the same four peaks, so it can not tell us where in the signal these frequencies are present. The Fourier Transform can not distinguish between the first two signals.
PS: The side lobes we see in the bottom frequency spectrum, is due to the discontinuity between the four different frequencies.
In trying to overcome this problem, scientists have come up with the Short-Time Fourier Transform. In this approach the original signal is splitted into several parts of equal length (which may or may not have an overlap) by using a sliding window before applying the Fourier Transform. The idea is quite simple: if we split our signal into 10 parts, and the Fourier Transform detects a specific frequency in the second part, then we know for sure that this frequency has occurred between  th and
th and  th of our original signal.
th of our original signal.
The main problem with this approach is that you run into the theoretical limits of the Fourier Transform known as the uncertainty principle. The smaller we make the size of the window the more we will know about where a frequency has occurred in the signal, but less about the frequency value itself. The larger we make the size of the window the more we will know about the frequency value and less about the time.
A better approach for analyzing signals with a dynamical frequency spectrum is the Wavelet Transform. The Wavelet Transform has a high resolution in both the frequency- and the time-domain. It does not only tell us which frequencies are present in a signal, but also at which time these frequencies have occurred. This is accomplished by working with different scales. First we look at the signal with a large scale/window and analyze ‘large’ features and then we look at the signal with smaller scales in order to analyze smaller features.
The time- and frequency resolutions of the different methods are illustrated in Figure 2.
In Figure 2 we can see the time and frequency resolutions of the different transformations. The size and orientation of the blocks indicate how small the features are that we can distinguish in the time and frequency domain. The original time-series has a high resolution in the time-domain and zero resolution in the frequency domain. This means that we can distinguish very small features in the time-domain and no features in the frequency domain.
Opposite to that is the Fourier Transform, which has a high resolution in the frequency domain and zero resolution in the time-domain.
The Short Time Fourier Transform has medium sized resolution in both the frequency and time domain.
The Wavelet Transform has:
- for small frequency values a high resolution in the frequency domain, low resolution in the time- domain,
- for large frequency values a low resolution in the frequency domain, high resolution in the time domain.
In other words, the Wavelet Transforms makes a trade-off; at scales in which time-dependent features are interesting it has a high resolution in the time-domain and at scales in which frequency-dependent features are interesting it has a high resolution in the frequency domain.
And as you can imagine, this is exactly the kind of trade-off we are looking for!
2.2 How does the Wavelet Transform work?
The Fourier Transform uses a series of sine-waves with different frequencies to analyze a signal. That is, a signal is represented through a linear combination of sine-waves.
The Wavelet Transform uses a series of functions called wavelets, each with a different scale. The word wavelet means a small wave, and this is exactly what a wavelet is.
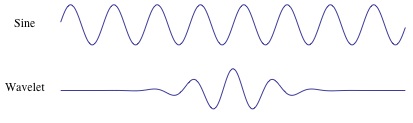
In Figure 3 we can see the difference between a sine-wave and a wavelet. The main difference is that the sine-wave is not localized in time (it stretches out from -infinity to +infinity) while a wavelet is localized in time. This allows the wavelet transform to obtain time-information in addition to frequency information.
Since the Wavelet is localized in time, we can multiply our signal with the wavelet at different locations in time. We start with the beginning of our signal and slowly move the wavelet towards the end of the signal. This procedure is also known as a convolution. After we have done this for the original (mother) wavelet, we can scale it such that it becomes larger and repeat the process. This process is illustrated in the figure below.
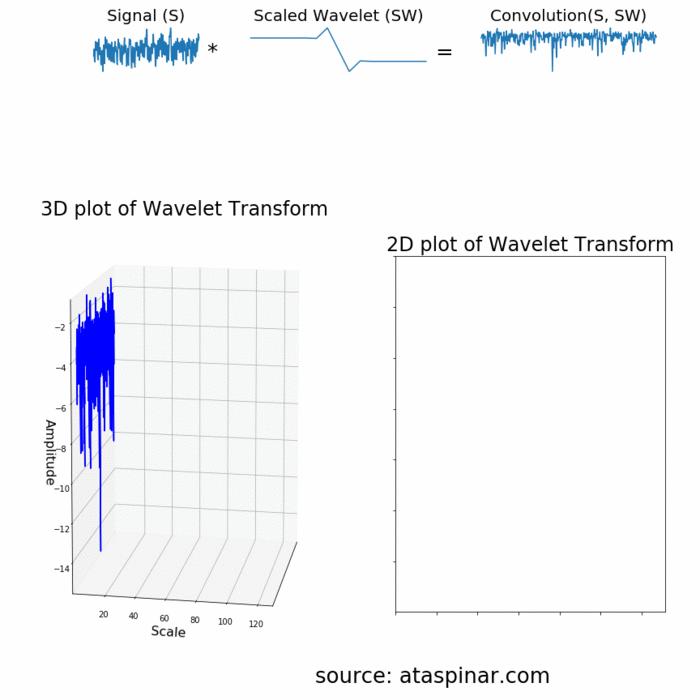
As we can see in the figure above, the Wavelet transform of an 1-dimensional signal will have two dimensions. This 2-dimensional output of the Wavelet transform is the time-scale representation of the signal in the form of a scaleogram.
Above the scaleogram is plotted in a 3D plot in the bottom left figure and in a 2D color plot in the bottom right figure.
PS: You can also have a look at this youtube video to see how a Wavelet Transform works.
So what is this dimension called scale? Since the term frequency is reserved for the Fourier Transform, the wavelet transform is usually expressed in scales instead. That is why the two dimensions of a scaleogram are time and scale. For the ones who find frequencies more intuitive than scales, it is possible to convert scales to pseudo-frequencies with the equation

where  is the pseudo-frequency,
is the pseudo-frequency,  is the central frequency of the Mother wavelet and
is the central frequency of the Mother wavelet and  is the scaling factor.
is the scaling factor.
We can see that a higher scale-factor (longer wavelet) corresponds with a smaller frequency, so by scaling the wavelet in the time-domain we will analyze smaller frequencies (achieve a higher resolution) in the frequency domain. And vice versa, by using a smaller scale we have more detail in the time-domain. So scales are basically the inverse of the frequency.
PS: PyWavelets contains the function scale2frequency to convert from a scale-domain to a frequency-domain.
2.3 The different types of Wavelet families
Another difference between the Fourier Transform and the Wavelet Transform is that there are many different families (types) of wavelets. The wavelet families differ from each other since for each family a different trade-off has been made in how compact and smooth the wavelet looks like. This means that we can choose a specific wavelet family which fits best with the features we are looking for in our signal.
The PyWavelets library for example contains 14 mother Wavelets (families of Wavelets):
|
1 2 3 4 5 |
import pywt print(pywt.families(short=False)) ['Haar', 'Daubechies', 'Symlets', 'Coiflets', 'Biorthogonal', 'Reverse biorthogonal', 'Discrete Meyer (FIR Approximation)', 'Gaussian', 'Mexican hat wavelet', 'Morlet wavelet', 'Complex Gaussian wavelets', 'Shannon wavelets', 'Frequency B-Spline wavelets', 'Complex Morlet wavelets'] |
Each type of wavelets has a different shape, smoothness and compactness and is useful for a different purpose. Since there are only two mathematical conditions a wavelet has to satisfy it is easy to generate a new type of wavelet.
The two mathematical conditions are the so-called normalization and orthogonalization constraints:
A wavelet must have 1) finite energy and 2) zero mean.
Finite energy means that it is localized in time and frequency; it is integrable and the inner product between the wavelet and the signal always exists.
The admissibility condition implies a wavelet has zero mean in the time-domain, a zero at zero frequency in the time-domain. This is necessary to ensure that it is integrable and the inverse of the wavelet transform can also be calculated.
Furthermore:
- A wavelet can be orthogonal or non-orthogonal.
- A wavelet can be bi-orthogonal or not.
- A wavelet can be symmetric or not.
- A wavelet can be complex or real. If it is complex, it is usually divided into a real part representing the amplitude and an imaginary part representing the phase.
- A wavelets is normalized to have unit energy.
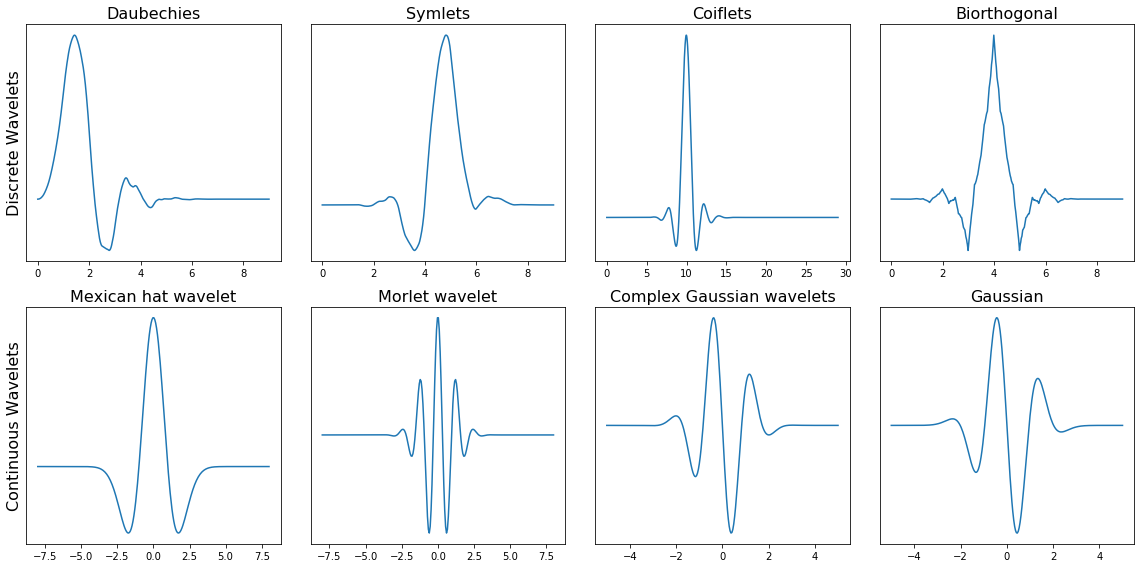
Below we can see a plot with several different families of wavelets.
The first row contains four Discrete Wavelets and the second row four Continuous Wavelets.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
discrete_wavelets = ['db5', 'sym5', 'coif5', 'bior2.4'] continuous_wavelets = ['mexh', 'morl', 'cgau5', 'gaus5'] list_list_wavelets = [discrete_wavelets, continuous_wavelets] list_funcs = [pywt.Wavelet, pywt.ContinuousWavelet] fig, axarr = plt.subplots(nrows=2, ncols=4, figsize=(16,8)) for ii, list_wavelets in enumerate(list_list_wavelets): func = list_funcs[ii] row_no = ii for col_no, waveletname in enumerate(list_wavelets): wavelet = func(waveletname) family_name = wavelet.family_name biorthogonal = wavelet.biorthogonal orthogonal = wavelet.orthogonal symmetry = wavelet.symmetry if ii == 0: _ = wavelet.wavefun() wavelet_function = _[0] x_values = _[-1] else: wavelet_function, x_values = wavelet.wavefun() if col_no == 0 and ii == 0: axarr[row_no, col_no].set_ylabel("Discrete Wavelets", fontsize=16) if col_no == 0 and ii == 1: axarr[row_no, col_no].set_ylabel("Continuous Wavelets", fontsize=16) axarr[row_no, col_no].set_title("{}".format(family_name), fontsize=16) axarr[row_no, col_no].plot(x_values, wavelet_function) axarr[row_no, col_no].set_yticks([]) axarr[row_no, col_no].set_yticklabels([]) plt.tight_layout() plt.show() |
PS: To see how all wavelets looks like, you can have a look at the wavelet browser.
Within each wavelet family there can be a lot of different wavelet subcategories belonging to that family. You can distinguish the different subcategories of wavelets by the number of coefficients (the number of vanishing moments) and the level of decomposition.
This is illustrated below in for the one family of wavelets called ‘Daubechies’.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
import pywt import matplotlib.pyplot as plt db_wavelets = pywt.wavelist('db')[:5] print(db_wavelets) *** ['db1', 'db2', 'db3', 'db4', 'db5'] fig, axarr = plt.subplots(ncols=5, nrows=5, figsize=(20,16)) fig.suptitle('Daubechies family of wavelets', fontsize=16) for col_no, waveletname in enumerate(db_wavelets): wavelet = pywt.Wavelet(waveletname) no_moments = wavelet.vanishing_moments_psi family_name = wavelet.family_name for row_no, level in enumerate(range(1,6)): wavelet_function, scaling_function, x_values = wavelet.wavefun(level = level) axarr[row_no, col_no].set_title("{} - level {}\n{} vanishing moments\n{} samples".format( waveletname, level, no_moments, len(x_values)), loc='left') axarr[row_no, col_no].plot(x_values, wavelet_function, 'bD--') axarr[row_no, col_no].set_yticks([]) axarr[row_no, col_no].set_yticklabels([]) plt.tight_layout() plt.subplots_adjust(top=0.9) plt.show() |

In Figure 6 we can see wavelets of the ‘Daubechies’ family (db) of wavelets. In the first column we can see the Daubechies wavelets of the first order ( db1), in the second column of the second order (db2), up to the fifth order in the fifth column. PyWavelets contains Daubechies wavelets up to order 20 (db20).
The number of the order indicates the number of vanishing moments. So db3 has three vanishing moments and db5 has 5 vanishing moment. The number of vanishing moments is related to the approximation order and smoothness of the wavelet. If a wavelet has p vanishing moments, it can approximate polynomials of degree p – 1.
When selecting a wavelet, we can also indicate what the level of decomposition has to be. By default, PyWavelets chooses the maximum level of decomposition possible for the input signal. The maximum level of decomposition (see pywt.dwt_max_level()) depends on the length of the input signal length and the wavelet (more on this later).
As we can see, as the number of vanishing moments increases, the polynomial degree of the wavelet increases and it becomes smoother. And as the level of decomposition increases, the number of samples this wavelet is expressed in increases.
2.4 Continuous Wavelet Transform vs Discrete Wavelet Transform
As we have seen before (Figure 5), the Wavelet Transform comes in two different and distinct flavors; the Continuous and the Discrete Wavelet Transform.
Mathematically, a Continuous Wavelet Transform is described by the following equation:
![]()
where  is the continuous mother wavelet which gets scaled by a factor of and translated by a factor of
is the continuous mother wavelet which gets scaled by a factor of and translated by a factor of  . The values of the scaling and translation factors are continuous, which means that there can be an infinite amount of wavelets. You can scale the mother wavelet with a factor of 1.3, or 1.31, and 1.311, and 1.3111 etc.
. The values of the scaling and translation factors are continuous, which means that there can be an infinite amount of wavelets. You can scale the mother wavelet with a factor of 1.3, or 1.31, and 1.311, and 1.3111 etc.
When we are talking about the Discrete Wavelet Transform, the main difference is that the DWT uses discrete values for the scale and translation factor. The scale factor increases in powers of two, so  and the translation factor increases integer values (
and the translation factor increases integer values (  ).
).
PS: The DWT is only discrete in the scale and translation domain, not in the time-domain. To be able to work with digital and discrete signals we also need to discretize our wavelet transforms in the time-domain. These forms of the wavelet transform are called the Discrete-Time Wavelet Transform and the Discrete-Time Continuous Wavelet Transform.
2.5 More on the Discrete Wavelet Transform: The DWT as a filter-bank.
In practice, the DWT is always implemented as a filter-bank. This means that it is implemented as a cascade of high-pass and low-pass filters. This is because filter banks are a very efficient way of splitting a signal of into several frequency sub-bands.
Below I will try to explain the concept behind the filter-bank in a simple (and probably oversimplified) way. It is necessary in order to understand how the wavelet transform actually works and can be used in practical applications.
To apply the DWT on a signal, we start with the smallest scale. As we have seen before, small scales correspond with high frequencies. This means that we first analyze high frequency behavior. At the second stage, the scale increases with a factor of two (the frequency decreases with a factor of two), and we are analyzing behavior around half of the maximum frequency. At the third stage, the scale factor is four and we are analyzing frequency behavior around a quarter of the maximum frequency. And this goes on and on, until we have reached the maximum decomposition level.
What do we mean with maximum decomposition level? To understand this we should also know that at each subsequent stage the number of samples in the signal is reduced with a factor of two. At lower frequency values, you will need less samples to satisfy the Nyquist rate so there is no need to keep the higher number of samples in the signal; it will only cause the transform to be computationally expensive. Due to this downsampling, at some stage in the process the number of samples in our signal will become smaller than the length of the wavelet filter and we will have reached the maximum decomposition level.
To give an example, suppose we have a signal with frequencies up to 1000 Hz. In the first stage we split our signal into a low-frequency part and a high-frequency part, i.e. 0-500 Hz and 500-1000 Hz.
At the second stage we take the low-frequency part and again split it into two parts: 0-250 Hz and 250-500 Hz.
At the third stage we split the 0-250 Hz part into a 0-125 Hz part and a 125-250 Hz part.
This goes on until we have reached the level of refinement we need or until we run out of samples.
We can easily visualize this idea, by plotting what happens when we apply the DWT on a chirp signal. A chirp signal is a signal with a dynamic frequency spectrum; the frequency spectrum increases with time. The start of the signal contains low frequency values and the end of the signal contains the high frequencies. This makes it easy for us to visualize which part of the frequency spectrum is filtered out by simply looking at the time-axis.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
import pywt x = np.linspace(0, 1, num=2048) chirp_signal = np.sin(250 * np.pi * x**2) fig, ax = plt.subplots(figsize=(6,1)) ax.set_title("Original Chirp Signal: ") ax.plot(chirp_signal) plt.show() data = chirp_signal waveletname = 'sym5' fig, axarr = plt.subplots(nrows=5, ncols=2, figsize=(6,6)) for ii in range(5): (data, coeff_d) = pywt.dwt(data, waveletname) axarr[ii, 0].plot(data, 'r') axarr[ii, 1].plot(coeff_d, 'g') axarr[ii, 0].set_ylabel("Level {}".format(ii + 1), fontsize=14, rotation=90) axarr[ii, 0].set_yticklabels([]) if ii == 0: axarr[ii, 0].set_title("Approximation coefficients", fontsize=14) axarr[ii, 1].set_title("Detail coefficients", fontsize=14) axarr[ii, 1].set_yticklabels([]) plt.tight_layout() plt.show() |

In Figure 7 we can see our chirp signal, and the DWT applied to it subsequently. There are a few things to notice here:
- In PyWavelets the DWT is applied with
pywt.dwt() - The DWT return two sets of coefficients; the approximation coefficients and detail coefficients.
- The approximation coefficients represent the output of the low pass filter (averaging filter) of the DWT.
- The detail coefficients represent the output of the high pass filter (difference filter) of the DWT.
- By applying the DWT again on the approximation coefficients of the previous DWT, we get the wavelet transform of the next level.
- At each next level, the original signal is also sampled down by a factor of 2.
So now we have seen what it means that the DWT is implemented as a filter bank; At each subsequent level, the approximation coefficients are divided into a coarser low pass and high pass part and the DWT is applied again on the low-pass part.
As we can see, our original signal is now converted to several signals each corresponding to different frequency bands. Later on we will see how the approximation and detail coefficients at the different frequency sub-bands can be used in applications like removing high frequency noise from signals, compressing signals, or classifying the different types signals.
PS: We can also use pywt.wavedec() to immediately calculate the coefficients of a higher level. This functions takes as input the original signal and the level  and returns the one set of approximation coefficients (of the n-th level) and n sets of detail coefficients (1 to n-th level).
and returns the one set of approximation coefficients (of the n-th level) and n sets of detail coefficients (1 to n-th level).
PS2: This idea of analyzing the signal on different scales is also known as multiresolution / multiscale analysis, and decomposing your signal in such a way is also known as multiresolution decomposition, or sub-band coding.
3.1 Visualizing the State-Space using the Continuous Wavelet Transform
So far we have seen what the wavelet transform is, how it is different from the Fourier Transform, what the difference is between the CWT and the DWT, what types of wavelet families there are, what the impact of the order and level of decomposition is on the mother wavelet, and how and why the DWT is implemented as a filter-bank.
We have also seen that the output of a wavelet transform on a 1D signal results in a 2D scaleogram. Such a scaleogram gives us detailed information about the state-space of the system, i.e. it gives us information about the dynamic behavior of the system.
The el-Nino dataset is a time-series dataset used for tracking the El Nino and contains quarterly measurements of the sea surface temperature from 1871 up to 1997. In order to understand the power of a scaleogram, let us visualize it for el-Nino dataset together with the original time-series data and its Fourier Transform.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 |
def plot_wavelet(time, signal, scales, waveletname = 'cmor', cmap = plt.cm.seismic, title = 'Wavelet Transform (Power Spectrum) of signal', ylabel = 'Period (years)', xlabel = 'Time'): dt = time[1] - time[0] [coefficients, frequencies] = pywt.cwt(signal, scales, waveletname, dt) power = (abs(coefficients)) ** 2 period = 1. / frequencies levels = [0.0625, 0.125, 0.25, 0.5, 1, 2, 4, 8] contourlevels = np.log2(levels) fig, ax = plt.subplots(figsize=(15, 10)) im = ax.contourf(time, np.log2(period), np.log2(power), contourlevels, extend='both',cmap=cmap) ax.set_title(title, fontsize=20) ax.set_ylabel(ylabel, fontsize=18) ax.set_xlabel(xlabel, fontsize=18) yticks = 2**np.arange(np.ceil(np.log2(period.min())), np.ceil(np.log2(period.max()))) ax.set_yticks(np.log2(yticks)) ax.set_yticklabels(yticks) ax.invert_yaxis() ylim = ax.get_ylim() ax.set_ylim(ylim[0], -1) cbar_ax = fig.add_axes([0.95, 0.5, 0.03, 0.25]) fig.colorbar(im, cax=cbar_ax, orientation="vertical") plt.show() def plot_signal_plus_average(time, signal, average_over = 5): fig, ax = plt.subplots(figsize=(15, 3)) time_ave, signal_ave = get_ave_values(time, signal, average_over) ax.plot(time, signal, label='signal') ax.plot(time_ave, signal_ave, label = 'time average (n={})'.format(5)) ax.set_xlim([time[0], time[-1]]) ax.set_ylabel('Signal Amplitude', fontsize=18) ax.set_title('Signal + Time Average', fontsize=18) ax.set_xlabel('Time', fontsize=18) ax.legend() plt.show() def get_fft_values(y_values, T, N, f_s): f_values = np.linspace(0.0, 1.0/(2.0*T), N//2) fft_values_ = fft(y_values) fft_values = 2.0/N * np.abs(fft_values_[0:N//2]) return f_values, fft_values def plot_fft_plus_power(time, signal): dt = time[1] - time[0] N = len(signal) fs = 1/dt fig, ax = plt.subplots(figsize=(15, 3)) variance = np.std(signal)**2 f_values, fft_values = get_fft_values(signal, dt, N, fs) fft_power = variance * abs(fft_values) ** 2 # FFT power spectrum ax.plot(f_values, fft_values, 'r-', label='Fourier Transform') ax.plot(f_values, fft_power, 'k--', linewidth=1, label='FFT Power Spectrum') ax.set_xlabel('Frequency [Hz / year]', fontsize=18) ax.set_ylabel('Amplitude', fontsize=18) ax.legend() plt.show() dataset = "http://paos.colorado.edu/research/wavelets/wave_idl/sst_nino3.dat" df_nino = pd.read_table(dataset) N = df_nino.shape[0] t0=1871 dt=0.25 time = np.arange(0, N) * dt + t0 signal = df_nino.values.squeeze() scales = np.arange(1, 128) plot_signal_plus_average(time, signal) plot_fft_plus_power(time, signal) plot_wavelet(time, signal, scales) |
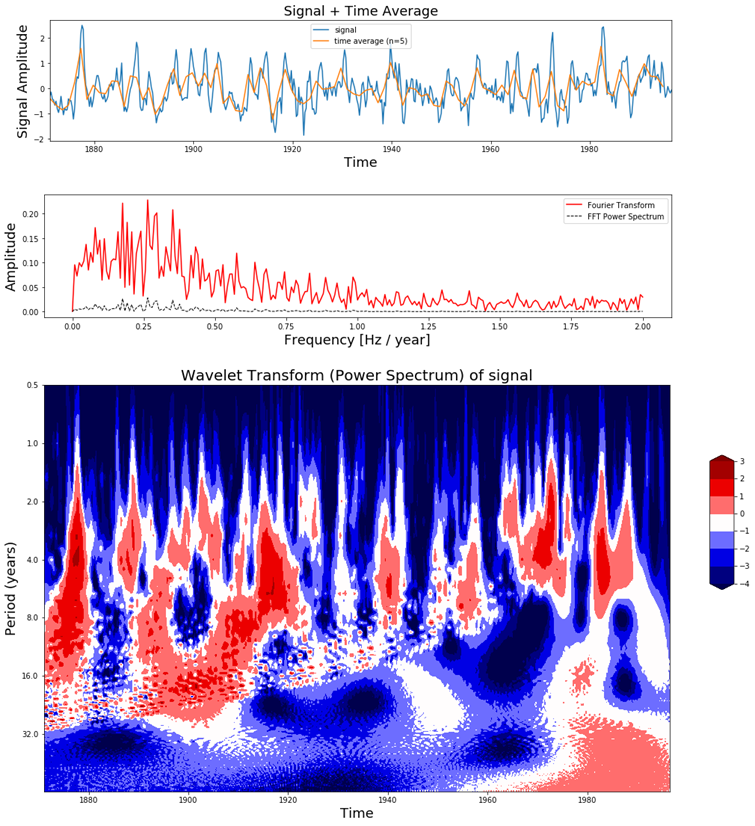
In Figure 8 we can see in the top figure the el-Nino dataset together with its time average, in the middle figure the Fourier Transform and at the bottom figure the scaleogram produced by the Continuous Wavelet Transform.
In the scaleogram we can see that most of the power is concentrated in a 2-8 year period. If we convert this to frequency (T = 1 / f) this corresponds with a frequency of 0.125 – 0.5 Hz. The increase in power can also be seen in the Fourier transform around these frequency values. The main difference is that the wavelet transform also gives us temporal information and the Fourier Transform does not. For example, in the scaleogram we can see that up to 1920 there were many fluctuations, while there were not so much between 1960 – 1990. We can also see that there is a shift from shorter to longer periods as time progresses. This is the kind of dynamic behavior in the signal which can be visualized with the Wavelet Transform but not with the Fourier Transform.
This should already make clear how powerful the wavelet transform can be for machine learning purposes. But to make the story complete, let us also look at how this can be used in combination with a Convolutional Neural Network to classify signals.
3.2 Using the Continuous Wavelet Transform and a Convolutional Neural Network for classification of signals
In section 3.1 we have seen that the wavelet transform of a 1D signal results in a 2D scaleogram which contains a lot more information than just the time-series or just the Fourier Transform. We have seen that applied on the el-Nino dataset, it can not only tell us what the period is of the largest oscillations, but also when these oscillations were present and when not.
Such a scaleogram can not only be used to better understand the dynamical behavior of a system, but it can also be used to distinguish different types of signals produced by a system from each other.
If you record a signal while you are walking up the stairs or down the stairs, the scaleograms will look different. ECG measurements of people with a healthy heart will have different scaleograms than ECG measurements of people with arrhythmia. Or measurements on a bearing, motor, rotor, ventilator, etc when it is faulty vs when it not faulty. The possibilities are limitless!
So by looking at the scaleograms we can distinguish a broken motor from a working one, a healthy person from a sick one, a person walking up the stairs from a person walking down the stairs, etc etc. But if you are as lazy as me, you probably don’t want to sift through thousands of scaleograms manually. One way to automate this process is to build a Convolutional Neural Network which can automatically detect the class each scaleogram belongs to and classify them accordingly.
What was the deal again with CNN? In previous blog posts we have seen how we can use Tensorflow to build a convolutional neural network from scratch. And how we can use such a CNN to detect roads in satellite images. If you are not familiar with CNN’s it is a good idea to have a look at these previous blog posts, since the rest of this section assumes you have some knowledge of CNN’s.
In the next few sections we will load a dataset (containing measurement of people doing six different activities), visualize the scaleograms using the CWT and then use a Convolutional Neural Network to classify these scaleograms.
3.2.1. Loading the UCI-HAR time-series dataset
Let us try to classify an open dataset containing time-series using the scaleograms and a CNN. The Human Activity Recognition Dataset (UCI-HAR) contains sensor measurements of people while they were doing different types of activities, like walking up or down the stairs, laying, standing, walking, etc. There are in total more than 10.000 signals where each signal consists of nine components (x acceleration, y acceleration, z acceleration, x,y,z gyroscope, etc). This is the perfect dataset for us to try our use case of CWT + CNN!
PS: For more on how the UCI HAR dataset looks like, you can also have a look at the previous blog post in which it was described in more detail.
After we have downloaded the data, we can load it into a numpy nd-array in the following way:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
def read_signals_ucihar(filename): with open(filename, 'r') as fp: data = fp.read().splitlines() data = map(lambda x: x.rstrip().lstrip().split(), data) data = [list(map(float, line)) for line in data] return data def read_labels_ucihar(filename): with open(filename, 'r') as fp: activities = fp.read().splitlines() activities = list(map(int, activities)) return activities def load_ucihar_data(folder): train_folder = folder + 'train/InertialSignals/' test_folder = folder + 'test/InertialSignals/' labelfile_train = folder + 'train/y_train.txt' labelfile_test = folder + 'test/y_test.txt' train_signals, test_signals = [], [] for input_file in os.listdir(train_folder): signal = read_signals_ucihar(train_folder + input_file) train_signals.append(signal) train_signals = np.transpose(np.array(train_signals), (1, 2, 0)) for input_file in os.listdir(test_folder): signal = read_signals_ucihar(test_folder + input_file) test_signals.append(signal) test_signals = np.transpose(np.array(test_signals), (1, 2, 0)) train_labels = read_labels_ucihar(labelfile_train) test_labels = read_labels_ucihar(labelfile_test) return train_signals, train_labels, test_signals, test_labels folder_ucihar = './data/UCI_HAR/' train_signals_ucihar, train_labels_ucihar, test_signals_ucihar, test_labels_ucihar = load_ucihar_data(folder_ucihar) |
The training set contains 7352 signals where each signal has 128 measurement samples and 9 components. The signals from the training set are loaded into a numpy ndarray of size (7352 , 128, 9) and the signals from the test set into one of size (2947 , 128, 9).
Since the signal consists of nine components we have to apply the CWT nine times for each signal. Below we can see the result of the CWT applied on two different signals from the dataset. The left one consist of a signal measured while walking up the stairs and the right one is a signal measured while laying down.
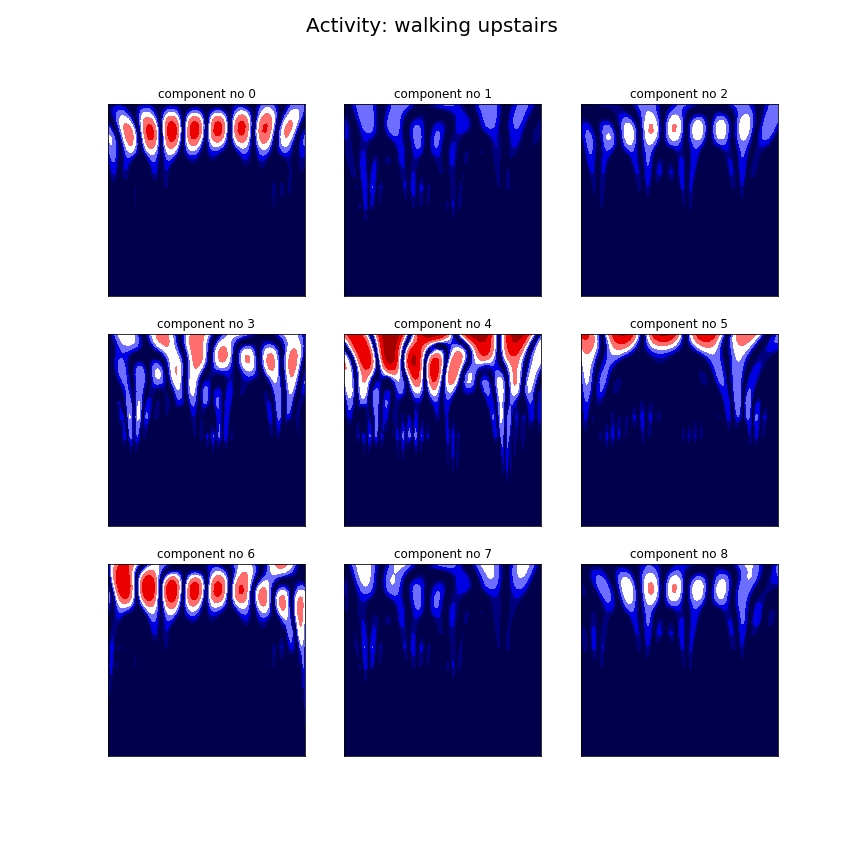

Figure 9. The CWT applied on two signals belonging to the UCI HAR dataset. Each signal has nine different components. On the left we can see the signals measured during walking upstairs and on the right we can see a signal measured during laying.
3.2.2 Applying the CWT on the dataset and transforming the data to the right format
Since each signal has nine components, each signal will also have nine scaleograms. So the next question to ask is, how do we feed this set of nine scaleograms into a Convolutional Neural Network? There are several options we could follow:
- Train a CNN for each component separately and combine the results of the nine CNN’s in some sort of an ensembling method. I suspect that this will generally result in a poorer performance since the inter dependencies between the different components are not taken into account.
- Concatenate the nine different signals into one long signal and apply the CWT on the concatenated signal. This could work but there will be discontinuities at location where two signals are concatenated and this will introduced noise in the scaleogram at the boundary locations of the component signals.
- Calculate the CWT first and thén concatenate the nine different CWT images into one and feed that into the CNN. This could also work, but here there will also be discontinuities at the boundaries of the CWT images which will feed noise into the CNN. If the CNN is deep enough, it will be able to distinguish between these noisy parts and actually useful parts of the image and choose to ignore the noise. But I still prefer option number four:
- Place the nine scaleograms on top of each other and create one single image with nine channels. What does this mean? Well, normally an image has either one channel (grayscale image) or three channels (color image), but our CNN can just as easily handle images with nine channels. The way the CNN works remains exactly the same, the only difference is that there will be three times more filters compared to an RGB image.
This process is illustrated in the Figure 11.

Below we can see the Python code on how to apply the CWT on the signals in the dataset, and reformat it in such a way that it can be used as input for our Convolutional Neural Network. The total dataset contains over 10.000 signals, but we will only use 5.000 signals in our training set and 500 signals in our test set.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
scales = range(1,128) waveletname = 'morl' train_size = 5000 test_size= 500 train_data_cwt = np.ndarray(shape=(train_size, 127, 127, 9)) for ii in range(0,train_size): if ii % 1000 == 0: print(ii) for jj in range(0,9): signal = uci_har_signals_train[ii, :, jj] coeff, freq = pywt.cwt(signal, scales, waveletname, 1) coeff_ = coeff[:,:127] train_data_cwt[ii, :, :, jj] = coeff_ test_data_cwt = np.ndarray(shape=(test_size, 127, 127, 9)) for ii in range(0,test_size): if ii % 100 == 0: print(ii) for jj in range(0,9): signal = uci_har_signals_test[ii, :, jj] coeff, freq = pywt.cwt(signal, scales, waveletname, 1) coeff_ = coeff[:,:127] test_data_cwt[ii, :, :, jj] = coeff_ uci_har_labels_train = list(map(lambda x: int(x) - 1, uci_har_labels_train)) uci_har_labels_test = list(map(lambda x: int(x) - 1, uci_har_labels_test)) x_train = train_data_cwt y_train = list(uci_har_labels_train[:train_size]) x_test = test_data_cwt y_test = list(uci_har_labels_test[:test_size]) |
As you can see above, the CWT of a single signal-component (128 samples) results in an image of 127 by 127 pixels. So the scaleograms coming from the 5000 signals of the training dataset are stored in an numpy ndarray of size (5000, 127, 127, 9) and the scaleograms coming from the 500 test signals are stored in one of size (500, 127, 127, 9).
3.2.3 Training the Convolutional Neural Network with the CWT
Now that we have the data in the right format, we can start with the most interesting part of this section: training the CNN! For this part you will need the keras library, so please install it first.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 |
import keras from keras.layers import Dense, Flatten from keras.layers import Conv2D, MaxPooling2D from keras.models import Sequential from keras.callbacks import History history = History() img_x = 127 img_y = 127 img_z = 9 input_shape = (img_x, img_y, img_z) num_classes = 6 batch_size = 16 num_classes = 7 epochs = 10 x_train = x_train.astype('float32') x_test = x_test.astype('float32') y_train = keras.utils.to_categorical(y_train, num_classes) y_test = keras.utils.to_categorical(y_test, num_classes) model = Sequential() model.add(Conv2D(32, kernel_size=(5, 5), strides=(1, 1), activation='relu', input_shape=input_shape)) model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2))) model.add(Conv2D(64, (5, 5), activation='relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Flatten()) model.add(Dense(1000, activation='relu')) model.add(Dense(num_classes, activation='softmax')) model.compile(loss=keras.losses.categorical_crossentropy, optimizer=keras.optimizers.Adam(), metrics=['accuracy']) model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(x_test, y_test), callbacks=[history]) train_score = model.evaluate(x_train, y_train, verbose=0) print('Train loss: {}, Train accuracy: {}'.format(train_score[0], train_score[1])) test_score = model.evaluate(x_test, y_test, verbose=0) print('Test loss: {}, Test accuracy: {}'.format(test_score[0], test_score[1])) *** Epoch 1/10 *** 5000/5000 [==============================] - 235s 47ms/step - loss: 0.3963 - acc: 0.8876 - val_loss: 0.6006 - val_acc: 0.8780 *** Epoch 2/10 *** 5000/5000 [==============================] - 228s 46ms/step - loss: 0.1939 - acc: 0.9282 - val_loss: 0.3952 - val_acc: 0.8880 *** Epoch 3/10 *** 5000/5000 [==============================] - 224s 45ms/step - loss: 0.1347 - acc: 0.9434 - val_loss: 0.4367 - val_acc: 0.9100 *** Epoch 4/10 *** 5000/5000 [==============================] - 228s 46ms/step - loss: 0.1971 - acc: 0.9334 - val_loss: 0.2662 - val_acc: 0.9320 *** Epoch 5/10 *** 5000/5000 [==============================] - 231s 46ms/step - loss: 0.1134 - acc: 0.9544 - val_loss: 0.2131 - val_acc: 0.9320 *** Epoch 6/10 *** 5000/5000 [==============================] - 230s 46ms/step - loss: 0.1285 - acc: 0.9520 - val_loss: 0.2014 - val_acc: 0.9440 *** Epoch 7/10 *** 5000/5000 [==============================] - 232s 46ms/step - loss: 0.1339 - acc: 0.9532 - val_loss: 0.2884 - val_acc: 0.9300 *** Epoch 8/10 *** 5000/5000 [==============================] - 237s 47ms/step - loss: 0.1503 - acc: 0.9488 - val_loss: 0.3181 - val_acc: 0.9340 *** Epoch 9/10 *** 5000/5000 [==============================] - 250s 50ms/step - loss: 0.1247 - acc: 0.9504 - val_loss: 0.2403 - val_acc: 0.9460 *** Epoch 10/10 *** 5000/5000 [==============================] - 238s 48ms/step - loss: 0.1578 - acc: 0.9508 - val_loss: 0.2133 - val_acc: 0.9300 *** Train loss: 0.11115437872409821, Train accuracy: 0.959 *** Test loss: 0.21326758581399918, Test accuracy: 0.93 |
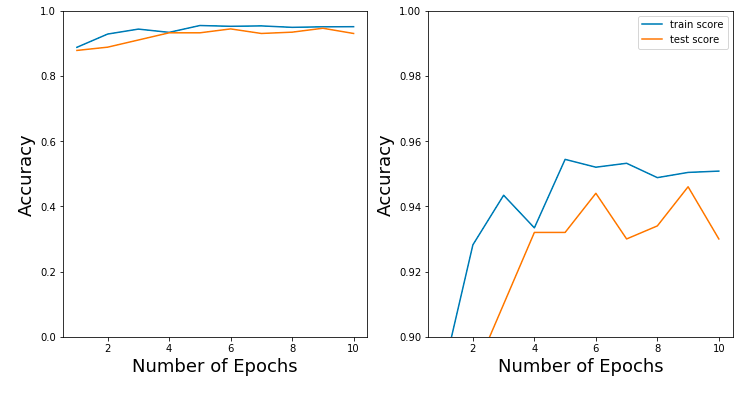
As you can see, combining the Wavelet Transform and a Convolutional Neural Network leads to an awesome and amazing result!
We have an accuracy of 94% on the Activity Recognition dataset. Much higher than you can achieve with any other method.
In section 3.5 we will use the Discrete Wavelet Transform instead of Continuous Wavelet Transform to classify the same dataset and achieve similarly amazing results!
3.3 Deconstructing a signal using the DWT
In Section 2.5 we have seen how the DWT is implemented as a filter-bank which can deconstruct a signal into its frequency sub-bands. In this section, let us see how we can use PyWavelets to deconstruct a signal into its frequency sub-bands and reconstruct the original signal again.
PyWavelets offers two different ways to deconstruct a signal.
- We can either apply
pywt.dwt()on a signal to retrieve the approximation coefficients. Then apply the DWT on the retrieved coefficients to get the second level coefficients and continue this process until you have reached the desired decomposition level. - Or we can apply
pywt.wavedec()directly and retrieve all of the the detail coefficients up to some level. This functions takes as input the original signal and the level and returns the one set of approximation coefficients (of the n-th level) and n sets of detail coefficients (1 to n-th level).
|
1 2 3 4 5 6 7 8 |
(cA1, cD1) = pywt.dwt(signal, 'db2', 'smooth') reconstructed_signal = pywt.idwt(cA1, cD1, 'db2', 'smooth') fig, ax = plt.subplots(figsize=(8,4)) ax.plot(signal, label='signal') ax.plot(reconstructed_signal, label='reconstructed signal', linestyle='--') ax.legend(loc='upper left') plt.show() |
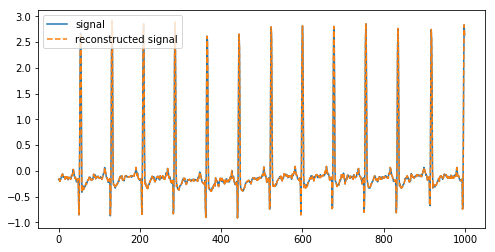
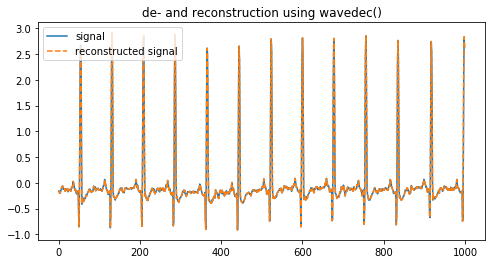
Above we have deconstructed a signal into its coefficients and reconstructed it again using the inverse DWT.
The second way is to use pywt.wavedec() to deconstruct and reconstruct a signal and it is probably the most simple way if you want to get higher-level coefficients.
|
1 2 3 4 5 6 7 8 9 |
coeffs = pywt.wavedec(signal, 'db2', level=8) reconstructed_signal = pywt.waverec(coeffs, 'db2') fig, ax = plt.subplots(figsize=(8,4)) ax.plot(signal[:1000], label='signal') ax.plot(reconstructed_signal[:1000], label='reconstructed signal', linestyle='--') ax.legend(loc='upper left') ax.set_title('de- and reconstruction using wavedec()') plt.show() |
3.4 Removing (high-frequency) noise using the DWT
In the previous section we have seen how we can deconstruct a signal into the approximation (low pass) and detail (high pass) coefficients. If we reconstruct the signal using these coefficients we will get the original signal back.
But what happens if we reconstruct while we leave out some detail coefficients? Since the detail coefficients represent the high frequency part of the signal, we will simply have filtered out that part of the frequency spectrum. If you have a lot of high-frequency noise in your signal, this one way to filter it out.
Leaving out of the detail coefficients can be done using pywt.threshold(), which removes coefficient values higher than the given threshold.
Lets demonstrate this using NASA’s Femto Bearing Dataset. This is a dataset containing high frequency sensor data regarding accelerated degradation of bearings.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
DATA_FOLDER = './FEMTO_bearing/Training_set/Bearing1_1/' filename = 'acc_01210.csv' df = pd.read_csv(DATA_FOLDER + filename, header=None) signal = df[4].values def lowpassfilter(signal, thresh = 0.63, wavelet="db4"): thresh = thresh*np.nanmax(signal) coeff = pywt.wavedec(signal, wavelet, mode="per" ) coeff[1:] = (pywt.threshold(i, value=thresh, mode="soft" ) for i in coeff[1:]) reconstructed_signal = pywt.waverec(coeff, wavelet, mode="per" ) return reconstructed_signal fig, ax = plt.subplots(figsize=(12,8)) ax.plot(signal, color="b", alpha=0.5, label='original signal') rec = lowpassfilter(signal, 0.4) ax.plot(rec, 'k', label='DWT smoothing}', linewidth=2) ax.legend() ax.set_title('Removing High Frequency Noise with DWT', fontsize=18) ax.set_ylabel('Signal Amplitude', fontsize=16) ax.set_xlabel('Sample No', fontsize=16) plt.show() |
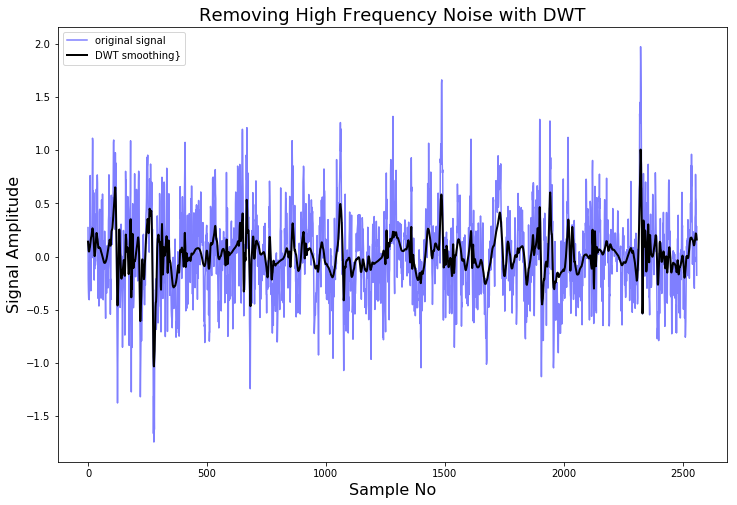
As we can see, by deconstructing the signal, setting some of the coefficients to zero, and reconstructing it again, we can remove high frequency noise from the signal.
People who are familiar with signal processing techniques might know there are a lot of different ways to remove noise from a signal. For example, the Scipy library contains a lot of smoothing filters (one of them is the famous Savitzky-Golay filter) and they are much simpler to use. Another method for smoothing a signal is to average it over its time-axis.
So why should you use the DWT instead? The advantage of the DWT again comes from the many wavelet shapes there are available. You can choose a wavelet which will have a shape characteristic to the phenomena you expect to see. In this way, less of the phenomena you expect to see will be smoothed out.
3.5 Using the Discrete Wavelet Transform to classify signals
In Section 3.2 we have seen how we can use a the CWT and a CNN to classify signals. Of course it is also possible to use the DWT to classify signals. Let us have a look at how this could be done.
3.5.1 The idea behind Discrete Wavelet classification
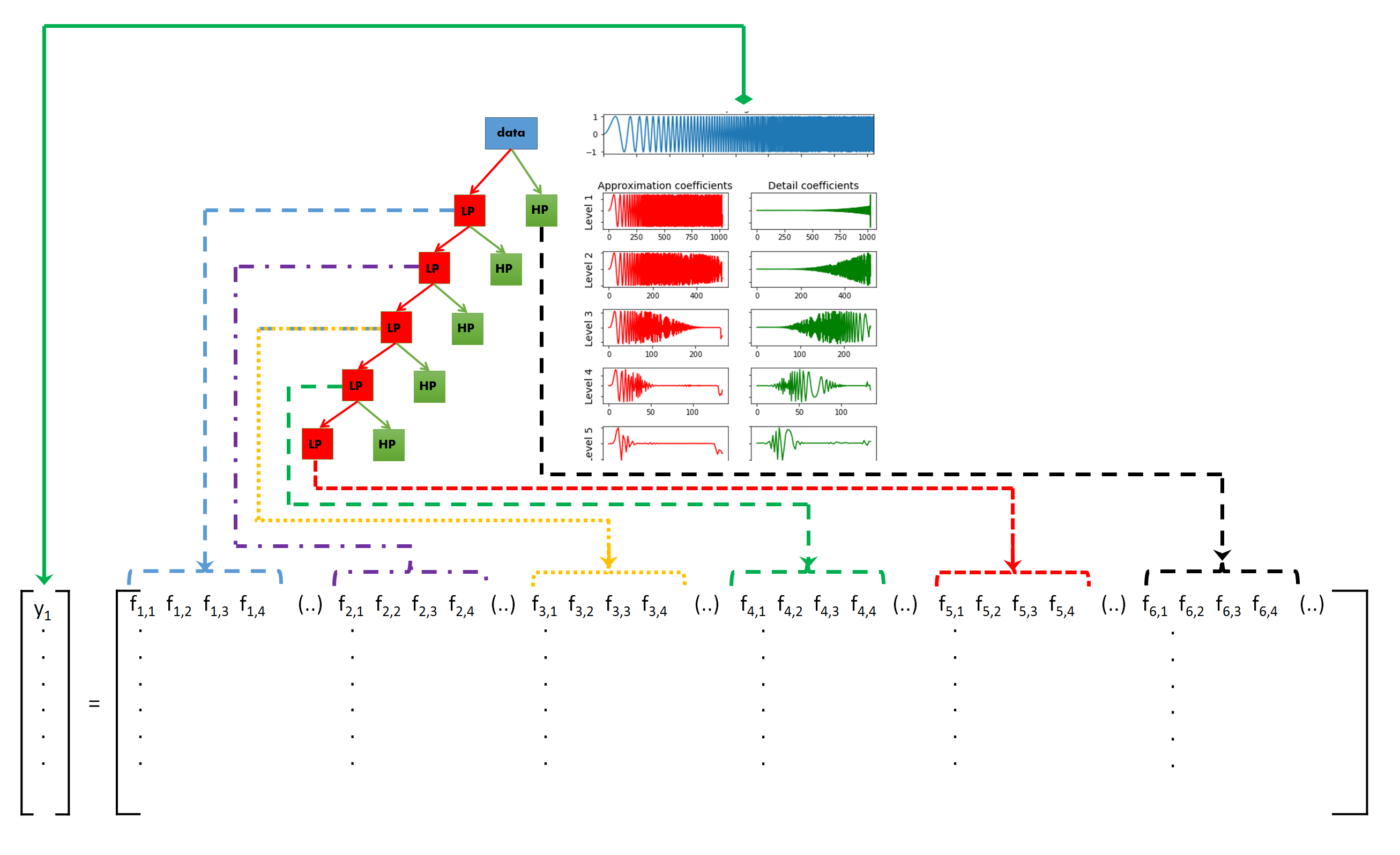
The idea behind DWT signal classification is as follows: The DWT is used to split a signal into different frequency sub-bands, as many as needed or as many as possible. If the different types of signals exhibit different frequency characteristics, this difference in behavior has to be exhibited in one of the frequency sub-bands. So if we generate features from each of the sub-band and use the collection of features as an input for a classifier (Random Forest, Gradient Boosting, Logistic Regression, etc) and train it by using these features, the classifier should be able to distinguish between the different types of signals.
This is illustrated in the figure below:
3.5.2 Generating features per sub-band
So what kind of features can be generated from the set of values for each of the sub-bands? Of course this will highly depend on the type of signal and the application. But in general, below are some features which are most frequently used for signals.
- Auto-regressive model coefficient values
- (Shannon) Entropy values; entropy values can be taken as a measure of complexity of the signal.
- Statistical features like:
- variance
- standard deviation
- Mean
- Median
- 25th percentile value
- 75th percentile value
- Root Mean Square value; square of the average of the squared amplitude values
- The mean of the derivative
- Zero crossing rate, i.e. the number of times a signal crosses y = 0
- Mean crossing rate, i.e. the number of times a signal crosses y = mean(y)
These are just some ideas you could use to generate the features out of each sub-band. You could use some of the features described here, or you could use all of them. Most classifiers in the scikit-learn package are powerful enough to handle a large number of input features and distinguish between useful ones and non-useful ones. However, I still recommend you think carefully about which feature would be useful for the type of signal you are trying to classify.
PS: There are a hell of a lot more statistical functions in scipy.stats. By using these you can create more features if necessary.
Let’s see how this could be done in Python for a few of the above mentioned features:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
def calculate_entropy(list_values): counter_values = Counter(list_values).most_common() probabilities = [elem[1]/len(list_values) for elem in counter_values] entropy=scipy.stats.entropy(probabilities) return entropy def calculate_statistics(list_values): n5 = np.nanpercentile(list_values, 5) n25 = np.nanpercentile(list_values, 25) n75 = np.nanpercentile(list_values, 75) n95 = np.nanpercentile(list_values, 95) median = np.nanpercentile(list_values, 50) mean = np.nanmean(list_values) std = np.nanstd(list_values) var = np.nanvar(list_values) rms = np.nanmean(np.sqrt(list_values**2)) return [n5, n25, n75, n95, median, mean, std, var, rms] def calculate_crossings(list_values): zero_crossing_indices = np.nonzero(np.diff(np.array(list_values) > 0))[0] no_zero_crossings = len(zero_crossing_indices) mean_crossing_indices = np.nonzero(np.diff(np.array(list_values) > np.nanmean(list_values)))[0] no_mean_crossings = len(mean_crossing_indices) return [no_zero_crossings, no_mean_crossings] def get_features(list_values): entropy = calculate_entropy(list_values) crossings = calculate_crossings(list_values) statistics = calculate_statistics(list_values) return [entropy] + crossings + statistics |
Above we can see
- a function to calculate the entropy value of an input signal,
- a function to calculate some statistics like several percentiles, mean, standard deviation, variance, etc,
- a function to calculate the zero crossings rate and the mean crossings rate,
- and a function to combine the results of these three functions.
The final function returns a set of 12 features for any list of values. So if one signal is decomposed into 10 different sub-bands, and we generate features for each sub-band, we will end up with 10*12 = 120 features per signal.
3.5.3 Using the features and scikit-learn classifiers to classify two ECG datasets.
So far so good. The next step is to actually use the DWT to decompose the signals in the training set into its sub-bands, calculate the features for each sub-band, use the features to train a classifier and use the classifier to predict the signals in the test-set.
We will do this for two time-series datasets:
- The UCI-HAR dataset which we have already seen in section 3.2. This dataset contains smartphone sensor data of humans while doing different types of activities, like sitting, standing, walking, stair up and stair down.
- PhysioNet ECG Dataset (download from here) which contains a set of ECG measurements of healthy persons (indicated as Normal sinus rhythm, NSR) and persons with either an arrhythmia (ARR) or a congestive heart failure (CHF). This dataset contains 96 ARR measurements, 36 NSR measurements and 30 CHF measurements.
After we have downloaded both datasets, and placed them in the right folders, the next step is to load them into memory. We have already seen how we can load the UCI-HAR dataset in section 3.2, and below we can see how to load the ECG dataset.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
def load_ecg_data(filename): raw_data = sio.loadmat(filename) list_signals = raw_data['ECGData'][0][0][0] list_labels = list(map(lambda x: x[0][0], raw_data['ECGData'][0][0][1])) return list_signals, list_labels ########## filename = './data/ECG_data/ECGData.mat' data_ecg, labels_ecg = load_ecg_data(filename) training_size = int(0.6*len(labels_ecg)) train_data_ecg = data_ecg[:training_size] test_data_ecg = data_ecg[training_size:] train_labels_ecg = labels_ecg[:training_size] test_labels_ecg = labels_ecg[training_size:] |
The ECG dataset is saved as a MATLAB file, so we have to use scipy.io.loadmat() to open this file in Python and retrieve its contents (the ECG measurements and the labels) as two separate lists.
The UCI HAR dataset is saved in a lot of .txt files, and after reading the data we save it into an numpy ndarray of size (no of signals, length of signal, no of components) = (10299 , 128, 9)
Now let us have a look at how we can get features out of these two datasets.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
def get_uci_har_features(dataset, labels, waveletname): uci_har_features = [] for signal_no in range(0, len(dataset)): features = [] for signal_comp in range(0,dataset.shape[2]): signal = dataset[signal_no, :, signal_comp] list_coeff = pywt.wavedec(signal, waveletname) for coeff in list_coeff: features += get_features(coeff) uci_har_features.append(features) X = np.array(uci_har_features) Y = np.array(labels) return X, Y def get_ecg_features(ecg_data, ecg_labels, waveletname): list_features = [] list_unique_labels = list(set(ecg_labels)) list_labels = [list_unique_labels.index(elem) for elem in ecg_labels] for signal in ecg_data: list_coeff = pywt.wavedec(signal, waveletname) features = [] for coeff in list_coeff: features += get_features(coeff) list_features.append(features) return list_features, list_labels X_train_ecg, Y_train_ecg = get_ecg_features(train_data_ecg, train_labels_ecg, 'db4') X_test_ecg, Y_test_ecg = get_ecg_features(test_data_ecg, test_labels_ecg, 'db4') X_train_ucihar, Y_train_ucihar = get_uci_har_features(train_signals_ucihar, train_labels_ucihar, 'rbio3.1') X_test_ucihar, Y_test_ucihar = get_uci_har_features(test_signals_ucihar, test_labels_ucihar, 'rbio3.1') |
What we have done above is to write functions to generate features from the ECG signals and the UCI HAR signals. There is nothing special about these functions and the only reason we are using two seperate functions is because the two datasets are saved in different formats. The ECG dataset is saved in a list, and the UCI HAR dataset is saved in a 3D numpy ndarray.
For the ECG dataset we iterate over the list of signals, and for each signal apply the DWT which returns a list of coefficients. For each of these coefficients, i.e. for each of the frequency sub-bands, we calculate the features with the function we have defined previously. The features calculated from all of the different coefficients belonging to one signal are concatenated together, since they belong to the same signal.
The same is done for the UCI HAR dataset. The only difference is that we now have two for-loops since each signal consists of nine components. The features generated from each of the sub-band from each of the signal component are concatenated together.
Now that we have calculated the features for the two datasets, we can use a GradientBoostingClassifier from the scikit-learn library and train it.
PS: If you want to know more about classification with the scikit-learn library, you can have a look at this blog post.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
cls = GradientBoostingClassifier(n_estimators=2000) cls.fit(X_train_ecg, Y_train_ecg) train_score = cls.score(X_train_ecg, Y_train_ecg) test_score = cls.score(X_test_ecg, Y_test_ecg) print("Train Score for the ECG dataset is about: {}".format(train_score)) print("Test Score for the ECG dataset is about: {.2f}".format(test_score)) ### cls = GradientBoostingClassifier(n_estimators=2000) cls.fit(X_train_ucihar, Y_train_ucihar) train_score = cls.score(X_train_ucihar, Y_train_ucihar) test_score = cls.score(X_test_ucihar, Y_test_ucihar) print("Train Score for the UCI-HAR dataset is about: {}".format(train_score)) print("Test Score for the UCI-HAR dataset is about: {.2f}".format(test_score)) *** Train Score for the ECG dataset is about: 1.0 *** Test Score for the ECG dataset is about: 0.93 *** Train Score for the UCI_HAR dataset is about: 1.0 *** Test Score for the UCI-HAR dataset is about: 0.95 |
As we can see, the results when we use the DWT + Gradient Boosting Classifier are equally amazing!
This approach has an accuracy on the UCI-HAR test set of 95% and an accuracy on the ECG test set of 93%.
3.6 Comparison of the classification accuracies between DWT, Fourier Transform and Recurrent Neural Networks
So far, we have seen throughout the various blog-posts, how we can classify time-series and signals in different ways. In a previous post we have classified the UCI-HAR dataset using Signal Processing techniques like The Fourier Transform. The accuracy on the test-set was ~91%.
In another blog-post, we have classified the same UCI-HAR dataset using Recurrent Neural Networks. The highest achieved accuracy on the test-set was ~86%.
In this blog-post we have achieved an accuracy of ~94% on the test-set with the approach of CWT + CNN and an accuracy of ~95% with the DWT + GradientBoosting approach!
It is clear that the Wavelet Transform has far better results. We could repeat this for other datasets and I suspect there the Wavelet Transform will also outperform.
What we can also notice is that strangely enough Recurrent Neural Networks perform the worst. Even the approach of simply using the Fourier Transform and then the peaks in the frequency spectrum has an better accuracy than RNN’s.
This really makes me wonder, what the hell Recurrent Neural Networks are actually good for. It is said that a RNN can learn ‘temporal dependencies in sequential data’. But, if a Fourier Transform can fully describe any signal (no matter its complexity) in terms of the Fourier components, then what more can be learned with respect to ‘temporal dependencies’.
It is no wonder that people already start talking about the fall of RNN / LSTM.
PS: The achieved accuracy using the DWT will depend on the features you decide to calculate, the wavelet and the classifier you decide to use. To give an impression, below are the accuracy values for the test set of the UCI-HAR and ECG datasets, for all of the wavelets present in PyWavelets, and for the most used 5 classifiers in scikit-learn.

We can see that there will be differences in accuracy depending on the chosen classifier. Generally speaking, the Gradient Boosting classifier performs best. This should come as no surprise since almost all kaggle competitions are won with the gradient boosting model.
What is more important is that the chosen wavelet can also have a lot of influence on the achieved accuracy values. Unfortunately I do not have an guideline on choosing the right wavelet. The best way to choose the right wavelet is to do a lot of trial-and-error and a little bit of literature research.
4. Final Words
In this blog post we have seen how we can use the Wavelet Transform for the analysis and classification of time-series and signals (and some other stuff). Not many people know how to use the Wavelet Transform, but this is mostly because the theory is not beginner-friendly and the wavelet transform is not readily available in open source programming languages.
MATLAB is one the few programming languages with a very complete Wavelet Toolbox. But since MATLAB has a expensive licensing fee, it is mostly used in the academic world and large corporations.
Among Data Scientists, the Wavelet Transform remains an undiscovered jewel and I recommend fellow Data Scientists to use it more often. I am very thankful to the contributors of the PyWavelets package who have implemented a large set of Wavelet families and higher level functions for using these wavelets. Thanks to them, Wavelets can now more easily be used by people using the Python programming language.
I have tried to give a concise but complete description of how wavelets can be used for the analysis of signals. I hope it has motivated you to use it more often and that the Python code provided in this blog-post will point you in the right direction in your quest to use wavelets for data analysis.
A lot will depend on the choices you make; which wavelet transform will you use, CWT or DWT? which wavelet family will you use? Up to which level of decomposition will you go? What is the right range of scales to use?
Like most things in life, the only way to master a new method is by a lot of practice. You can look up some literature to see what the commonly used wavelet type is for your specific problem, but do not make the mistake of thinking whatever you read in research papers is the holy and you don’t need to look any further. 🙂
PS: You can also find the code in this blog-post in five different Jupyter notebooks in my Github repository.
96 gedachten over “A guide for using the Wavelet Transform in Machine Learning”
Firstly thank you, great article, I had been aware of wavelets for some decades as an Electrical/Controls engineer but never fully grasped even the basic relationship to Fourier transforms of them until now.
In your closing summary you ask “This really makes me wonder, what the hell Recurrent Neural Networks are actually good for. “.
I contemplate that RNNs are more like direct computational logic than intelligence or thought as we call it – they basically give a static output if given a static input. How does this allow spontaneous “thought” or “ideas” to emerge or be synthesised?
The human brain has waves, it seems the role of these waves in consciousness, thought and memory is only just starting to be contemplated in any detail.
In the physical world in order for there to be waves, or oscillations, generally a system needs to have an appropriately changed phase signal fed back back to an input or earlier processing stage. (Controls theory have negative feedback in the basic PID building block, but it depends on the transfer function of the part of the network/system you feed back around to the input of).
A network model that had this structure might not be statically stable, but if effectively critically damped, it could be dynamically stable – continuous waves, and of many frequencies and amplitudes and localised at different scales.
Maybe the physical connections between the neurons are only part of the mystery of what makes us human, no matter the number and complexity.
Is there also a need energy for waves continuously “circulating” and constantly creating some kind of stimulation at different times to different parts of the neuronal network to allow us to hallucinate our reality. Interrupting these waves too severely maybe throws the pattern into an unrecoverable, or decaying mode. (Which also then begs the question, how do they start at the beginning of life?)
Could the multiple waves, localised at overlapping scales combine to create wavelets, in a manner not unlike the creation a Fourier impulse function? And would that then allow the brain to generate complexity out of simplicity and also analyse observed patterns in both a time and frequency based way? (I am totally out of my depth here by now, just expanding a spontaneous idea)
Do the brains waves could also explain death and loss of consciousness where the physical structure is effectively unchanged but something is lost, the measurable thing being the brain waves. If it were to be the waves that are lost and they are part of what makes us conscious, self aware and gift us emergent thinking?
Disclaimer : This is all just semi random thoughts I had while reading the article, I am not more than an amateur in most of these matters and welcome informed comment.
Thank you for this awesome article. I’m working with wavelets and deep learning for signal processing, but I was not sure to well understand maths under the hood. Your examples are absolutely meaningful and of great help. Your the man! Thanks again for sharing.
for the code for figure 1, get_fft_values module if from which library. numpy of scipy. it is not mentioned
For anybody looking for the answer in the future the fft is from scipy
https://github.com/taspinar/siml/blob/master/siml/signal_analysis_utils.py
I enjoyed every part of the article and along the way I had a lot of ideas. Thanks a lot.
Great article! Really helpful! Thank you so much for sharing all these things!
Inedible overview – thank you for such an easy to understand and replicate guide!
What a great article, Thank you so muchh !
Awesome article!
this is really helpful, Thanks!
I do not quite grasp the how the DWT algorithm is working (maybe that comes from a lack of understanding of what a filter bank is actually doing). Would you say that a first pass of the DWT is doing a convolution between the signal and the wavelet (and would that be the approximation coefficients?, in that case how do you get the detailed ones?). then the second pass is doing the same on the approximation coefficents, etc. Is that right?
Hi Julien,
Thank you for your response. In regards to your question, I think you almost got it right.
The DWT on any signal results in a set of two coefficient; approximation which correspond with the lower frequencies and detail coefficients which correspond with the higher frequencies. Lets call these cA1 and cD1.
The second pass is done on the approximation coefficients; so the sub-band containing the lower frequencies is split into approximation and detail coefficients again. Lets call them cA2 and cD2.
This is done up to the maximum decomposition level n.
As you can see in the documentation of pywt.wavedec() the final output is [cAn, cDn, cDn-1, …, cD2, cD1].
If you want, you can also have a look at this simple example of the DWT.
Hi, I was trying to run your code but it doesn’t have the code for the below function. Can you please help me with that?
get_ave_values(time, signal, average_over)
See: https://github.com/taspinar/siml/blob/master/notebooks/WV2%20-%20Visualizing%20the%20Scaleogram%2C%20time-axis%20and%20Fourier%20Transform.ipynb
hello , Nice Job ! I will test on my dataset .
I have some questions looking at the code using CNN after CWT.
you have 6 classes but then you update de num_classes var to 7 ? (this can induce incorrect values for accuracy…) or it must be 7 for some reason ?
Also at the end of the notebook you plot the history.acc saying it is the test set … for the test set it must be history.val_acc that is a lit bit lower …
nice job in general of course ! 😉
Hi Rui,
Thank you for the feedback.
I had forgotten that the labels for the classes are starting with index 1, while keras assumes the labeling for the classes start with index 0.
I have updated the code as well as the figures is in the blog-post and on the notebook on GitHub.
PS: The accuracy does get a small percentage better, but I would say it falls within the range of fluctuations.
hello !
the CWT operation is so slow… or is just me ? is there any way to speed up this transformation ?
Thanks !
Rui
I assume were talking about an input signal with a high sampling rate and lots of samples. I also experienced the same problem. I dont have a definite solution but I think you should have a look at the scales youre using.
Also see https://groups.google.com/forum/m/#!topic/pywavelets/Z1ThBeG2oIo
hello,
I have test this method on my dataset but the model does not converge … with LSTM it converges 10% above base line (it is a difficult dataset to learn). But the conclusion is that LSTM is better at least in my case-study. I have another 3 case studies to test … lets see.
Also I have found some bugs/issues in your notebook…
– The N_CLASSES are 6 in the datset but in the network but you have 7.
– your normalization is not well done… I see you copy paste the CNN from some example with mnist and here normalization are made with min=0 and max=255 (that is why you divide the all dataset by 255) but in your case the min max values are around 6 …
– You shuffle the data-set before you divide into train test … I dont know if there is some “continuity” in the collection of data but if there is you end up with very similar examples in the test dataset and train … For LSTM if your batch is not size 1 this has implications because the “CELL” memory is reset only when it changes batch on train…
All this “bugs” mainly the one with 7 classes and wrong normalizations makes the all final results uncertainty… I will try to correct this issues and see if the ACC is really that . And retrain one LSTM exactly with the same train/test data (no randoms and no truncated data to 5000 and 500 like you do … all equal for both models).
well… I have clean your code :
-nb_classes 6 not 7
-no shuffling data
-correct normalization
-correct acc_VAL plot (not history.acc)
and the conclusions are not good for this method
Epoch 10/10
4000/4000 [==============================] – 21s 5ms/step – loss: 0.0691 – acc: 0.9650 – val_loss: 0.2654 – val_acc: 0.8940
Test loss: 0.2653581520216439
Test accuracy: 0.8939999990463257
I “blow” the computer memory and takes about 1 hour to build the CWT features …
If you apply a simple CNN directly to the data you have this in 10 seconds :
Epoch 71/400
4000/4000 [==============================] – 3s 785us/step – loss: 0.1284 – acc: 0.9535 – val_loss: 0.4725 – val_acc: 0.9420
I did not apply LSTM yet … I will come back in a second …
using LSTM bidirectional :
4000/4000 [==============================] – 262s 66ms/step – loss: 0.3157 – acc: 0.8733 – val_loss: 0.2348 – val_acc: 0.8980
(iteration 26)
I think the best method is CNN directly (with out CWT) for this case study since we have segmented time-series and memory is not important …
PS: CWT only introduce entropy to all problem … can be discarded
Hi Jorge,
Thanks for the feedback as well.
It was already mentioned that the num of classes is wrong. I have updated this in the code and on the notebook on GitHub.
The errors you mentioned (‘normalization by 255’ / val_acc) have been removed in the code and run again. Results are very similar to the previous version.
I understand that for this simple toy-dataset applying a CNN directly to the signal also gives really good results. However, I am curious whether that will still be the case for more complicated datasets or whether the CWT does provide an additional benefit.
In any case, CNN’s are a very powerful tool and by the looks of your code outperform LSTM’s for this dataset. I believe there have also been numerous papers written on CNN’s outperforming LSTM’s.
Very impressive and elaborate research, thanks for helping my research on wavelets analysis.
Hi jorge, I have updated the code for num_classes and normalization of the data.
In regards to the shuffling, I do think it is necessary since in this dataset the classes are not randomly ordered (see y_train.txt / y_test.txt).
In any case, the files are splitted in a train and a test set in the original dataset, so there is no need to worry about that.
PS: What are the other use cases?
Hello, I have been toying with this data set (this blog motivated me to do so 😉 ) I have reach state of the art results (better than 1st place on kaggle using exactly the UCI raw data sets – some papers present good results but they cheat altering the dataset (e.g. you can see on the confusion matrix the number of examples is different than the original in the test set …)) and I am going to publish my method and I would like to reference this work … Do you have any article on this ? what is the best way to refer to this work in an article?
Hi Rui,
Pretty cool of you. Hope you can publish a good article!
I am also thinking of publishing an article, but I did not have time so far to write anything up. So you only have this blog-post to refer to ATM.
I don’t know exactly it works, but in the past my blog has been referred to with either
a) only a reference to the page,
b) Name, blog title, blog url
c) Name, blog title, blog url, github page
You can have a look at some examples at https://scholar.google.nl/scholar?hl=nl&as_sdt=0%2C5&q=ataspinar.com&btnG=
In any case, good luck with the article.
I will use this :
@online{wletCNN,
author = {Ahmet Taspinar},
title = {A guide for using the Wavelet Transform in Machine Learning.},
year = 2018,
url = {https://ataspinar.com/2018/12/21/a-guide-for-using-the-wavelet-transform-in-machine-learning/},
urldate = {2018-12-21}
}
Thanks a lot for this blog post. It is super useful!
Thanks a lot for this blog post.
I have a question.
I think that the result of the CWT pre-processing of the signal will be positive and negative and Max will be different. By the way,
How did you Nomalize the value before putting it in deep running?
Great post!
I have a small question. I try to use “Image.fromarray” save 3-d data to a RGB image. However, the image looks quite different from the plot in Figure 8 and 9. Do you why?
Should I use plot image to train?
Thanks a lot.
problem fixed by using
.astype(np.uint8)
Thanks a lot for this blog post.
I think that the result of the CWT pre-processing of the signal will be positive and negative and Max will be different. By the way,
How did you Nomalize the value before putting it in deep running?
Hi Seoul,
This really depends on the input signal. For example, if it has a high sampling rate there is a large chance there will outliers in the signal and standard scaling of min/max scaling do not perform optimally. Then I scale with percentiles instead of the min and max. Like this:
def normalize_signal(signal):
p99 = np.nanpercentile(signal, 99.9)
p01 = np.nanpercentile(signal, 0.1)
height = p99-p01
normalized_signal = ((signal – p01) / (height/2)) – 1
return [p01, p99, normalized_signal]
I guess this corresponds with the RobustScaler. You can also have a look here for a comparison of the different scalers.
https://scikit-learn.org/stable/auto_examples/preprocessing/plot_all_scaling.html
Hello,
Thank you so much for this post, it’s super enlightening! I have a few minor questions though.
For the CWT scaleogram in Figure 8, how did you observe the “shift from shorter to longer periods as time progresses”? It seems the exact opposite to me, for as the time progresses, the peaks of positive periods (red parts) shift upward to the region where periods are shorter?
Also, I’m currently dealing with some seismic signals, which are better processed by continous wavelets like Morlet or Ricker Wavelet, but I’m using LGBM. So I wonder if there’s a way to extract features from CWT like you did in section 2.5 from each sub-band on DWT? I see that pywt.cwt() returns a 1 dimension coefficient array just like DWT, but it seems I need to manually enter each scale? I’m kinda confused…
Once again really appreciate your time and insights!
Hi Yijan,
Thanks for the comment!
I was referring to the later period 1960 and upwards, where you can also see higher values in the longer periods (32 years).
pywt.cwt()actually returns two items: coefficients and frequencies.frequencies is indeed a one dimensional array, but coefficients is an two dimensional array!
print(coefficients.shape) –> (127, 503)
print(frequencies.shape) –> (127,)
If have never tried it myself, but you can try to generate features out of each row of the ‘coefficients’ array (or out of every n rows).
Good luck!
Thank you so much Ahmet for a wonderful explanation of wavelet transform and its application. I learned alot from your blog. Keep doing the great work! May God bless you 🙂
Thank you very much for the great article. Just a minor point: Figure 15 maybe should be the last red adds with all the green, right? Again, thanks very much!
Hi Hay,
I don’t know exactly what you mean. It could be that the colors are not correct.
The idea is that the output of pywt.wavedec(), which contains a list of sets of coefficients is used as input for a feature generator function.
As long as you are consistent, the order of the coefficients does not really matter.
Hi Ahmet — I almost never comment on anything on the internet … just wanted to say that this is a tremendously well-written and helpful article. Your figures get straight to the fundamental mechanisms and practical benefits of wavelets. AND you have exactly the right amount of theory to help me get some intuition about what is happening, without a bunch of detailed math that just obscures things. And straightforward code with real data.
Great stuff…. thanks for your time in putting this together.
Hi, thanks a lot for this article. I’ve great results using your lowpassfilter function, but I’m facing a random issue with it, as sometimes, its output is of different shape with one more sample than in the input.
Any idea why?
Thanks anyway.
Great and helpful article, thanks a lot.
I implemented the DWT successfully on a time series, and then I used the level 5 of approximation coefficients and level 1, level 2, level 3, level 4, and level5 of detail coefficients (cA5, cD5, cD4, cD3, cD2, and cD1) as train for machine learning.
But I am facing with a problem, because of decrease the number of samples by each level; I can’t match the different levels of decomposition together.
Could you please help me with that?
Hi
For the CNN + CWT example, I am not getting the same accuracy as you:
—
5000/5000 [==============================] – 32s 6ms/step – loss: 0.4976 – acc: 0.8670 – val_loss: 0.6622 – val_acc: 0.7460
Epoch 2/10
5000/5000 [==============================] – 37s 7ms/step – loss: 0.1874 – acc: 0.9300 – val_loss: 0.5222 – val_acc: 0.8140
Epoch 3/10
5000/5000 [==============================] – 45s 9ms/step – loss: 0.1634 – acc: 0.9378 – val_loss: 0.4913 – val_acc: 0.8460
Epoch 4/10
5000/5000 [==============================] – 47s 9ms/step – loss: 0.1698 – acc: 0.9428 – val_loss: 0.6755 – val_acc: 0.7320
Epoch 5/10
5000/5000 [==============================] – 51s 10ms/step – loss: 0.1681 – acc: 0.9388 – val_loss: 0.6140 – val_acc: 0.7860
Epoch 6/10
5000/5000 [==============================] – 52s 10ms/step – loss: 0.1501 – acc: 0.9450 – val_loss: 0.6650 – val_acc: 0.7020
Epoch 7/10
5000/5000 [==============================] – 51s 10ms/step – loss: 0.1266 – acc: 0.9530 – val_loss: 0.3773 – val_acc: 0.8420
Epoch 8/10
5000/5000 [==============================] – 53s 11ms/step – loss: 0.0983 – acc: 0.9630 – val_loss: 0.6188 – val_acc: 0.7080
Epoch 9/10
5000/5000 [==============================] – 51s 10ms/step – loss: 0.2276 – acc: 0.9372 – val_loss: 0.4089 – val_acc: 0.8020
Epoch 10/10
5000/5000 [==============================] – 52s 10ms/step – loss: 0.1920 – acc: 0.9492 – val_loss: 0.4823 – val_acc: 0.7540
Train loss: 0.14876973194935286, Train accuracy: 0.9456
Test loss: 0.48233831304311753, Test accuracy: 0.7540000004768371
—
The test accuracy is only 75% compared to your 94%. Do you have any ideas on why this could be the case?
Very good explanation with proper code…….
Hi,
Could I ask how the threshold for the de-noising of the signal was determined?
In the above example, 0.63*np.nanmax(signal) was used. Why was the value 0.63 select?
Hi, thanks for the great article! Really good resource.
Is there a reason why we use only the approximation coefficients to feed into the training set, instead of using all the detail coefficients and just the last approximation coefficients? I would think that there would be a redundancy of features if we use the approximation coefficients only.
Dear Ahmet, thank you for this awesome article and it really helpful!
However I have two question from the section 3.1 Visualizing the State-Space using the Continuous Wavelet Transform.
First, What is dt in line 71. Second, on line 9, what is the purposing of scales and what is the justification of selecting the range 1-128?
Really appreciate for the time taken entertaining this question.
Line 71: dt=0.25
Line 9: [coefficients, frequencies] = pywt.cwt(signal, scales, waveletname, dt)
Line 75 scales = np.arange(1, 128),
Hi Balandong,
Thank you for the compliment. It is much appreciated.
The el-Nino dataset contains quarterly measurements, that is why I have set the timedelta dt equal to 0.25.
Scales is the wavelet equavalence of frequency. In the domain of wavelet analysis it has become the standard to use scales instead of frequencies. However, as explained in the text, scales increase inversely proportional to frequency.
You can convert a scale to the corresponding frequency value with
pywt.scale2frequency(), so if you know which frequency range the phenomenon you are looking for will exhibit itself you can choose the scale-range accordingly.So for the above settings, a scale of 128 corresponds to a frequency of 0.0155, which corresponds to a period of 64 years.
But I guess a scale of 100 or 120 would also have been OK.
For choosing the right scales, it might also be a big help to look at papers dealing with similar datasets.
Hi!
In your ECG example it seems that you decompose the whole waveform into wavelet coefs. This implies an offline mode of processing. Could you comment on the online mode, when the signal arrives in small chunks. What is the optimal size of data, how waveform length affects feature dimension? In FFT we can focus on local signal properties, feeding the signal frame by frame. Does it make sense to do so in wavelet practice? Despite wavelet capturing multiscale features, does it make sense to work frame by frame for limiting feature size or staying online with signal reading?
Hi Sergei,
I guess the wavelet transform is less useful in an online mode (especially since it is good in localizing the frequency contents in the time-domain), but depending on the size of the small chunks it can be a little less useful or not useful at all. It also strongly depends on your choice of wavelet. For example, if the small chunks contain 60 samples (1 chunk per minute) you have four levels of decomposition with ‘db2’ and only one with ‘db9’ or higher.
Amazing article! It help me a lot!
Thank you for making the codes available!
Desar Ahmet,
First thank you for the excellent document.
Follwing the question of Balandong, how did you calculate the scale 128 with frequency (1/T)?
All the best
Hi Milton.
With pywt you can calculate it as follows:
“0.25 / pywt.scale2frequency(‘cmor’,128)”
>>> 64.0
Hi,
thank you for your very interesting post. I was wondering what was the ‘gt’ parameter within the
calculate_crossings() funtion :
zero_crossing_indices = np.nonzero(np.diff(np.array(list_values) & gt; 0))[0]
Futhermore is it possible that it would be: ‘,’ instead of the: ‘;’ in the line above
I think “>” is wordpress fucking up the greater than sign “>”
Hi, i think i could not get something. Which code part of “3.2.3 Training the Convolutional Neural Network with the CWT” apply wavelet transform?
Thanks
pywt.cwt() applies the continuous wavelet transform.
Hello, Please I am new here on python. I have gone through this code, in section 3.2.1 line 32 and 33 seems to be giving me error, please can someone help check this for me? Also, I will like to know what this train_signals = np.transpose(np.array(train_signals), (1, 2, 0)) does.
Wow awesome article! thank you. I have signal with quite some phase noise and amplitude noise. I hope this is the way to go. Will let you know.
This a great article! But i dont no how to download de UCI HAR dataset with more than 10.000 signal , can you help me what bloq o must see? Thank you.
Hi! First, Thanks for the awesome article! But I have a questions about the CWT part.
Why using “power” for visualizing while “coefficient” for CNN classification?
In plot_wavelet function,
dt = time[1] – time[0]
[coefficients, frequencies] = pywt.cwt(signal, scales, waveletname, dt)
power = (abs(coefficients)) ** 2
period = 1. / frequencies
levels = [0.0625, 0.125, 0.25, 0.5, 1, 2, 4, 8]
contourlevels = np.log2(levels)
fig, ax = plt.subplots(figsize=(15, 10))
im = ax.contourf(time, np.log2(period), np.log2(power), contourlevels, extend=’both’,cmap=cmap)
————————————————————————————
In CNN
for ii in range(0,train_size):
if ii % 1000 == 0:
print(ii)
for jj in range(0,9):
signal = uci_har_signals_train[ii, :, jj]
coeff, freq = pywt.cwt(signal, scales, waveletname, 1)
coeff_ = coeff[:,:127]
train_data_cwt[ii, :, :, jj] = coeff_
test_data_cwt = np.ndarray(shape=(test_size, 127, 127, 9))
for ii in range(0,test_size):
if ii % 100 == 0:
print(ii)
for jj in range(0,9):
signal = uci_har_signals_test[ii, :, jj]
coeff, freq = pywt.cwt(signal, scales, waveletname, 1)
coeff_ = coeff[:,:127]
test_data_cwt[ii, :, :, jj] = coeff_
uci_har_labels_train = list(map(lambda x: int(x) – 1, uci_har_labels_train))
uci_har_labels_test = list(map(lambda x: int(x) – 1, uci_har_labels_test))
Many thanks in advance!
Thank you for your great posting! it helped me a lot!
by the way, I am curious way you add dt in function pywt.cwt()? as,
[coefficients, frequencies] = pywt.cwt(signal, scales, waveletname, dt)
Thank for an awesome post.
I was wondering if you can share the code to obtain Figure 9, which is the scalogram from CWT on the 9 signals of the HAR dataset. I’ve tried to obtain them, but I have some troubles to get the same results, it is pretty similar, but tends to be messy.
Thanks in advance
What seems to be the problem? It is simply a matplotlib subplots with ncols=3 and nrows=3…
I have trouble using plt.contourf. My code to try to obtain one of the scalograms is
#plot
fs = 50
scales = np.arange(1,128) #len(of the signal)
t = np.arange(len(uci_har_signals_train[0, :, 3]))/fs
[coefficients, frequencies] = pywt.cwt(uci_har_signals_train[0, :, 3],scales, ‘morl’, 1)
#levels = frequencies[-1:0:-1]
levels = 20
#contourlevels = (levels)
fig,ax = plt.subplots(figsize = (10,8))
im = ax.contourf(t, frequencies,np.log10(np.abs(coefficients)**2),levels,cmap=plt.cm.seismic)
#yticks = 2**np.arange(np.ceil(frequencies.min()), np.ceil((frequencies.max())))
#ax.set_yticks([])
#ax.set_yticklabels([])
ax.invert_yaxis()
ylim = ax.get_ylim()
#ax.set_ylim(ylim[0], -1)
But the result is not similar to the one you obtain.
Thank you for the response
Anyone here interested in Wavelets?
Follow my dissertation about PCBs Fast Wavelet Transform.
Please, download and read it!
Link: http://repositorio.unicamp.br/jspui/handle/REPOSIP/338849
An excellent article, thank you so much for it!
It convinced me to investigate further onto wavelet transformation topic.
Dear Ahmet
I really thank you for this explanation. I have some questions and I hope you get free time to give me your miracle guidance.
I’m really sad that whenever we are talking about signal and signal processing all get focus on multivariate ….
I am working with time series forecasting and I have some problems with padding and signal extension when using wavelet.
as you know distortion happens in two edges of the finite signal(time series here) then we should use a signal extension method to extend signal then our main signal will be unaffected.
in time series maybe the historical data available to extend but it is the main problem for the right edge because we do not know the future value(this problem is much more important for online models) so we use prediction engines to get artifact future samples to extend the signal.
some formula to calculate the number of samples we need is (FilterLenght-1)*(2**(DecLevel-1)
could you please tell me or give an example code(more realistic) how can we use artificial data to extend the signal appropriately for the different levels to reduce the distortions
Sincerely I am waiting for your replay
Best Regards
Hi David,
Have you solved this problem? I am facing the same issue. I could reproduce the improvement of accuracies for time series forecast from using LSTM to dwt+LSTM as shown in the literature using historical data. But as you said, in real life we would face padding problems on the right edge and I couldn’t find how they solve this problem in the literature. Would be very grateful if you have solved this issue and don’t mind to share the solution here.
Thanks in advance
Anyone here interested in Wavelets?
Please, check out my Master dissertation about PCBs inspection using Fast Wavelet Transform:
http://repositorio.unicamp.br/jspui/bitstream/REPOSIP/338849/1/Bonello_DanielKatz_M.pdf
Thank you 😉
Thanks for a really fantastic article! I’ve been trying to do something similar with a very large dataset, but the resulting array is too large to fit in memory. I have 12 scaleograms to layer into the CNN. I know Keras has the “flow_from_directory” capability, but I can only figure out how to do this with a 3-layer RGB image. Is there anything you’d recommend for applying your approach with larger data sets? Many thanks!
Nice Article ! Is it possible to discuss the rationale behind the data transformation for generating the ytick values and what do they mean intuitively ? And also what is the reason behind applying invert_yaxis. I am trying out the approach on a dataset that I have and inverting the y-axis gives extremely different spectrogram
Regarding the right edge problem referred to above: Use of wavelets is all fine in theory but practically useless for time series forecasting. When applying a wavelet transform to time series data, you effectively are leaking future information backwards through the series. This is why it gives such great results when training a model but will not work in the real world as we don’t have the future values.
Hi Conor,
Thank you for this reaction. That is why I also first split the time-series into a training set and a test set. The training set is up to t0 and a the test set from t0 up to the end.
Since the wavelet transform is only applied on the training part of the signal it is impossible to incorporate future information which is in the test set.
Hey ahmet , Thank you for the big work here . in the following code :
def get_ecg_features(ecg_data, ecg_labels, waveletname):
list_features = []
list_unique_labels = list(set(ecg_labels))
———–>>>> list_labels = [list_unique_labels.index(elem) for elem in ecg_labels]
for signal in ecg_data:
list_coeff = pywt.wavedec(signal, waveletname)
features = []
for coeff in list_coeff:
——–> features += get_features(coeff)
list_features.append(features)
return list_features, list_labels
i didnt understand clearly what you did exactly in the lines I mentionned there , can you please explain more , really appreciate .
It looks like I am LabelEncoding the labels by replacing them with their index number (of list_unique_labels).
You can also use scikit-learns Label Encoder of course. If you do it like above I would recommend to also sort the list_unique_labels so it is always in the same order.
Second:
get_features() returns a list which is automatically concatenated with “features”.
Fantastic writeup, incredibly detailed and easy to follow. Thank you!
Thank You! I agree with you, there are not many resources online talking about DWT in a practical way, I truly appreciate your post!
Hi Ahmet,
Thank you for the great content, it helped me a lot.
I have a question. In feature extraction steps you are using the output from the “pywt.wavedec” function. The “pywavelet” documentation states that the output is [cA_n, cD_n, cD_n-1, …, cD2, cD1] (n is the level), however in your figure it looks like the features are created from only the approximation coefficients. Don’t the features come from the last approximation coefficients and all the detail coefficients?
Hi Saeb,
Thank a lot. You are right actually, looks like the arrows are pointing from the wrong coefficients.
I’ll update it asap.
I have tried exactly the same code, but frequency domain plot does not come exactly the same given above. What is the problem??
def get_fft_values(y_values, T, N, f_s):
f_values = np.linspace(0.0, 1.0/(2.0*T), N//2)
fft_values_ = fft(y_values)
fft_values = 2.0/N * np.abs(fft_values_[0:N//2])
return f_values, fft_values
t_n=1
N = 100000
T = t_n / N
f_s = 1/T
xa = np.linspace(0, t_n, num=N)
xb = np.linspace(0, t_n/4, num=N//4)
frequencies = [4, 30, 60, 90]
y1a, y1b = np.sin(2*np.pi*frequencies[0]*xa), np.sin(2*np.pi*frequencies[0]*xb)
y2a, y2b = np.sin(2*np.pi*frequencies[1]*xa), np.sin(2*np.pi*frequencies[1]*xb)
y3a, y3b = np.sin(2*np.pi*frequencies[2]*xa), np.sin(2*np.pi*frequencies[2]*xb)
y4a, y4b = np.sin(2*np.pi*frequencies[3]*xa), np.sin(2*np.pi*frequencies[3]*xb)
composite_signal1 = y1a + y2a + y3a + y4a
composite_signal2 = np.concatenate([y1b, y2b, y3b, y4b])
f_values1, fft_values1 = get_fft_values(composite_signal1, T, N, f_s)
f_values2, fft_values2 = get_fft_values(composite_signal2, T, N, f_s)
fig, axarr = plt.subplots(nrows=2, ncols=2, figsize=(12,8))
axarr[0,0].plot(xa, composite_signal1)
axarr[1,0].plot(xa, composite_signal2)
axarr[0,1].plot(f_values1, fft_values1)
axarr[1,1].plot(f_values2, fft_values2)
(…)
plt.tight_layout()
plt.show()
I think this article is very important and informative, it helped me a lot. I’m currently studying the hypothesis of using wavelet transform as a preprocessing step in my machine learning model. I have a small problem/dilemma with this and it would be really nice if you could answer. So, i have these signals to split into train/test but to transform the signlas with wavelet transform i can’t shuffle the data right? I feel like it doesn’t make sense to transform a shuffled signal, but if i don’t do it my test data won’t include important values to test. And I think i can’t transform the whole signal and only after split since there will be leakage to the test set right? So, any ideas how to help me? Thank you so much!
Hi Mariana,
I think you are doing an “out of time” split to split each signal into a part train and part test, right?
Because you could also split it “out of sample” where each signal is either in train or in test.
In any case you should first split and then transform to prevent leakage.
If you have a signals of 100 sec, you could split it into 50s of train and 50s of test. If you have unequal lengths for train/ test for example 80s for train and 20s for test you could also apply a windowing function to split the train part into blocks of 20s.
If you want to apply windowing, you have to make sure there are no blocks which are both in the train and test set.
It really depends on what you want to predict I guess. If it is an ‘event’ / anomaly which can occur at any part of the signal randomly and you apply windowing it will be in some of the blocks and not in others.
If it is something where the location in the time-series is relevant like “remaining useful life time prediction” then you should also keep track of which part of the signal you get each block and maybe use it as an additional feature
Thank you! That actually cleared my min 🙂
Hi, very interesting blog post.
Could you share the part of the code to obtain: Figure 9. The CWT applied on two signals belonging to the UCI HAR dataset ?
I used plt.matshow, but the resolution is different, and i do not know which signal you used for comparison. Thank you very much.
I like those no_zero_crossings and no_mean_crossings features that gave you 86% of the result right away. How did you come up with that? Also, do you quite understand their connection with Walsh basis?
Hi sir,
How can we change the scaling factor in stationary wavelet transform (swt).
In python wavelets they were providing as this command for swt, pywt.swt2(arr, ‘bior1.3’, level=1, start_level=0):
I am working for images for extracting features from facial images.
Thank you
hi .i read this article . it is very useful. i enjoyed it .
i want decompose an image with non subsampled shearlet transform(NSST) . can help me . please
hi . i read this article . it is very useful.i enjoyed it .
i want decompose an image with non subsampled shearlet transform . can help me . please
Hello Ahmet,
Awesome article, awesome blog, great job!.
I have some questions about wavelets:
1.- Have you any good reference(s) to deepen knowledge in the wavelet world?
2.- How to choose the right wavelet for a given application? I see, the question has been answered almost in the last paragraph, try, test, test and try… is there any advice or suggestion other to burn the cpu?.
3.- In the case of a time series forecasting, what approach do you suggest?
3a.- Use the components as individual signals, forecast it and add the forecasted series as the final forecast?
3b.- Extract some features, as in the case of time series classification, and try to build a regressor from it?
Thank you very much for you time
JM Vericat
Hi,
Under 3.2.3, when training the CNN, I got an error message for the following code:
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
The message was: module ‘keras.utils’ has no attribute ‘to_categorical’.
The following code worked for me:
y_train = keras.utils.np_utils.to_categorical(y_train, num_classes)
y_test = keras.utils.np_utils.to_categorical(y_test, num_classes)
Thanks for the amazing work!
Thanks!
how i did this using matlab please for level 3 to plot power spectral density
It’s the best tutorial on DWT I ever read! Thank you!
Thank you very much for this tutorial. I have learned a lot. Do you think one could use DWT/FFT with clustering method in the same way ?
I have a set of non-stationary current data, which unfortunately are not labelled. But they can obviously be grouped into 4 clusters (failure modes).
Can you maybe recommend me a signal processing method to implement K-Mean or something else ?
Many thanks in advance.
Thank you for a wonderful tutorial, I would like to point out a modification in figure 15. If i am correct, the features extracted are all from the high pass, detailed coefficients for the all the levels except the final level. The final level has only the approximate coeffections. I am understanding this from the output of pywt.wavedec()
The picture however, shows features extracted from approximate coefficients from all levels. This might be confusing for the reader. Please correct it if it is a mistake. Thanks.
Really appreciate this detailed practical use of Wavelet transforms. You are a good educator.